
Biopharma trends 2024, midyear update: what is relevant as of June-July 2024
Discover the latest trends in biopharma for 2024, including AI-driven drug discovery, personalized medicine, and other technologies transforming the industry.

Avenga Labs is keeping their finger on the pulse of technology. They analyze thousands of tech news items every week, picking the most interesting events and filtering the noise . . . so that you don’t have to.
I tried to avoid the topic altogether, but I found a relation to the enterprise world in which Avenga operates, so let’s address this news elephant head first.
The Internet is filled with news about NFTs (Non-fungible tokens); about another digital asset sold at a very high speculative price. There are even recommendations to invest in NFTs instead of crypto, as the prices on art pieces which seemed to be worthless yesterday are now worth thousands of dollars or even more.
The NFT gold rush is definitely here and the speculative bubble is raising prices and creating inflated expectations.
The idea started innocently enough and was designed to protect and track the ownership and access to digital assets created by artists. Digital assets are especially important now in the creation process and they are extremely vulnerable to copying, as is everything that is digital in the 21st century.
The topic isn’t new as it started around 2016 as a hackathon in order to create a digital ledger based solution that tracks asset rights and ensures they cannot be modified; so blockchain seemed a natural choice.
The creators of the solution rushed (which they admit themselves) and skipped some important things in the proof of concept solution. But the enthusiasm was so big that it was launched anyway and copycat solutions copied the original idea. Again, this is a very profound idea that protects ownership in a decentralized way, which is democratic and based on publicly available blockchains.
Actually there are several flaws, both in the idea and the implementation, however, this type of news doesn’t hit the headlines. So, Avenga Labs has taken up the torch and wants to make sure you are aware of both sides of this phenomenon.
First of all, NFTs do not protect rights; usually (well, always) they don’t relate to rights as they are not a DRM and not a legal document. NFTs are kind of an agreement, which may or may not be backed up by the law.
Second, if someone buys access to the digital asset, it’s just buying a link to the asset. Blockchain is not optimized for storing large amounts of data, but for short hashes and transactions. No digital assets are stored inside the safe blockchain store, so there’s no guarantee that the link will even exist a few weeks after the purchase. Even when assuming the good will of all the parties involved (very optimistic), all online services have a finite lifetime and the link which works today is highly unlikely to work later.
Third, there is the issue of the real value of the asset vs. its speculative value. Someone stated that you’ll never be able to convert this asset to real money, so no houses or yachts will be bought. Of course it’s each individual’s decision to take any financial risks, but it’s better to be warned before making it.
Fourth, is the issue of power consumption and a CO2 footprint. In the gold rush nobody seems to care too much about it, but the power usage is enormous. There are estimations of the numbers of nuclear reactors that are needed to sustain the growth of traffic for NFTs. NFT brokers are promising to move away from the Ethereum blockchain to lighter alternatives.
The target blockchain technology here is called Flow. It also enables more ownership data protection features than implementations based on Ethereum.
Time will tell if and when these power efficiency optimizations and migrations happen.
In times of volatile economic conditions, which will unfortunately continue due to the late and inefficient response to the pandemic, people are looking for new ways to invest their money and they are accepting options which they never would have accepted before. But when we add to it lowered bank interest rates and the decline in trust of governments and global institutions, it seems somewhat understandable.
→We highlight Digital Transformation in Finance
What really disappoints me is that here’s another time when blockchain and digital ledgers are used as backend technology just like with crypto currencies. When the pyramid falls, the bad name will be attached to a set of technologies, . . . again. Now everything is on the rise, both crypto and NFTs, but inevitable correction will come and make many people frustrated.
In my opinion, any additional damage to the image of digital ledgers will make enterprise adoption of blockchain even harder than it is now. Crypto, now IFTs, all steer people’s attention from the really great use cases of digital ledgers, which can help with the more pressing issues of humanity and businesses.
→ Blockchain based system for COVID-19 test results

Apache Kafka is a very popular streaming platform, which has won the hearts and minds of developers and architects all over the world. This platform helps to stream data very efficiently between internal and external systems, which is the key to faster digital solutions based on multiple sources, and both data and API driven ecosystems. Kafka’s typical use case is to process millions of messages per second (which means business transaction) in a reliable and cost efficient way. And, Kafka has proved its worth, in addition to being available both on-prem in containerized environments and in all the major cloud offerings.
What is happening now in the project is a major change of the architecture. Why? Isn’t a rule of engineering not to fix the things that are working. Yes, it is, but that would impede the progress and close the doors for innovation.
Kafka is currently using two paradigms for data processing and workflow management, one is Kafka and the other is Zookeeper.
The reasons are historical. When Kafka started, they wanted to use a scheduler and picked up Zookeeper which was readily available at the time and could focus on the data streaming functionalities.
But, the old friend started to become a bottleneck and now the decision has been made to refactor the products and replace Zookeeper with a native solution.
Zookeeper used a different processing paradigm than Kafka, and having two different paradigms in the same product is rarely a good point. It might be acceptable, for years even, but at some point the drawbacks will overshadow the benefits.
Kafka is built around an efficient log, while Zookeeper however is an “idiosyncratic filesystem/trigger on top of a consistent log”. The two philosophies of an event store with pub/sub functionalities combined together led to additional complexity and this always results in lower stability, robustness and performance characteristics.
To illustrate the change, let’s borrow an image from the Kafka team blog.
The left side shows the current architecture and the right side the new one.
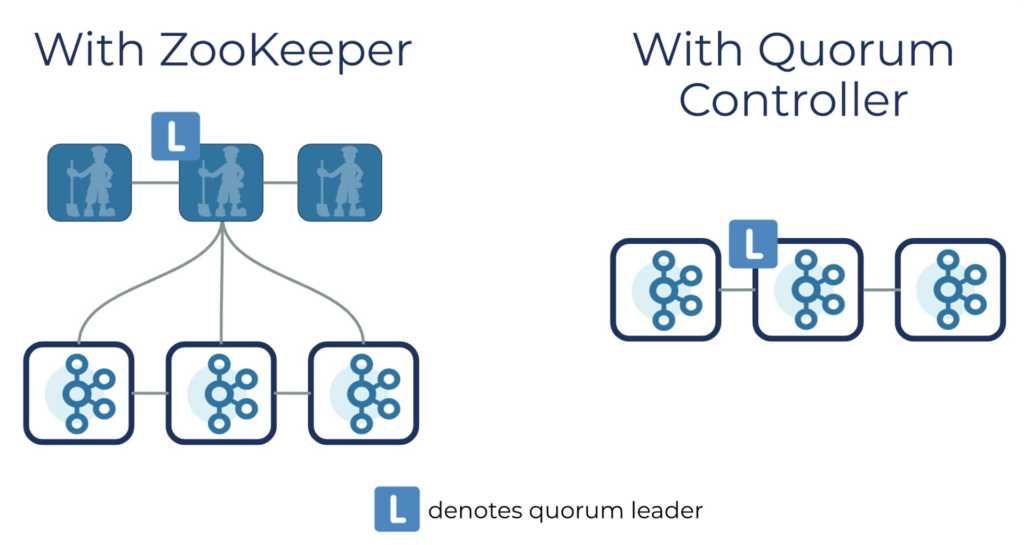
Simplification means there are less things to fail and there are no longer two different models that were forced to work together. It means stability and robustness.
Less cross-paradigm connections also means better performance, along with easier management of security and resources. Now it’s more like one unified organism than two different ones.
The team showed that using this simplified model, in case of node failures, Kafka will recover orders of magnitude faster than before. This is critical for real life applications, when from time to time things fail under heavy loads and need to recover quickly.
The number of partitions on the same resources can be multiplied now as the overhead of a new Quorum Controller is much less than that of the Zookeeper engine.
And remember, it’s just the first version of the new architecture and further optimizations are certainly to come. First of all, they needed to make a bold move by cutting out Zookeeper.
There’s also a benefit for smaller and the smallest workload scenarios.
Kafka used to be considered as an overhead for simpler cases, management complexity, and more lightweight messaging queues were used instead. Well, after this change, Kafka will be optimized even for workloads on the single machine, even single process level, and be able to scale to thousands of nodes. So the lower scalability end will enable avoiding switching tools and target the designated Kafka platform from the beginning of even the smallest of POCs/MVPs.
The first build of the project without Zookeeper has already been published online. Not all the features from Kafka are available in this version, it should be considered as tech preview at this point.
I keep my fingers crossed and congratulations to the Kafka team on their boldness to simplify the architecture and deliver an even better messaging platform for all of us. It will take months to finalize this move, and in between there will be two architectures in play.
The inevitable has happened. Public face image data sources used by virtually all the data scientists in the world are blurred now. It’s surprising news for the entire data science community. The dependency on these large image sets is high, many examples will fail, many models as well, but it’s not the end of the world.
First of all there are copies used to create those models which will remain as the source to further optimize them.
Second, there are other sets which are publicly available in their unaltered version.
Third, there are many images which weren’t showing people’s faces and these images were not altered.
Fourth, the researchers behind Image Net, claim that “Blurring the faces did not affect the performance of several object-recognition algorithms trained on ImageNet”.
Let’s believe that, but they just specified examples of what is working, people use these image sets in different ways and for different reasons, which they cannot be aware of. So we cannot treat it as assurance for any particular research case.
This is definitely a problem for citizen data scientists, smaller companies, startups, which cannot afford to gather tons of data like Internet giants do every second. Blurred data is not the same as a non-blurred image, even though the consequences for the ML algorithms may not be as dire as it seems at first glance. Other papers promise only fractional losses of accuracy, but every professional data scientist knows that it may make or break their ML algorithms, turning them from failed experiments to useful for real life applications.
Of course this also means opportunities for companies selling such data as part of their business models. Now it will be easier to sell their sets as ImageNet has been alternated.
Will next open image sources follow the suit? I’d bet they do. Privacy is very easily enforced in such simple cases like publishing public images, much harder in the case of internet behemoths hiding many details inside their infrastructures and organizations.
Database of Facebook data consisting of actual names, emails, phone numbers was published online and is available for free.
It’s highly likely that your personal data is already leaked. The phone numbers and emails are likely already in the wrong hands.
Facebook is trying to downplay this massive leak of personal data explaining it’s not… the latest data. Such an ultimate violation of privacy and personal data protection failure on such a large scale is going to showcase how really strong or weak the data protection regulations are.
We can only speculate about the penalties in billions, however they won’t hurt the social media giant too much. It happened before with Google and others.
Maybe this time the consequences will be more dire for Facebook, but the process will be long and results not immediate. Is half a billion people enough to do something serious about it? We are all about to see.
At the time of writing this there’s no response from Facebook whatsoever.
I’m afraid, from the enterprise perspective, it will be used as an example that even Facebook cannot protect basic data of its customers so probably nobody can. And it could result in more acceptance for lowering our effective data protection rights by any organization. “It just happens from time to time, it may happen to everyone”. I hope I’m deeply wrong about the impact of this massive leak and people will stand up for their rights instead of easily coping with “inevitable” leaks of their personal data.

Discover the latest trends in biopharma for 2024, including AI-driven drug discovery, personalized medicine, and other technologies transforming the industry.

Learn how to build a cross-functional team and how they can spur innovation, foster collaboration, and accelerate problem-solving in your business.

In the wake of the devastating missile strike on July 8, 2024, that severely damaged Ukraine’s largest children’s hospital, Okhmatdyt, Avenga announced a donation of 1,000,000 UAH to support the hospital’s urgent restor…

Discover recent insights into the Microsoft 365 tech community, explore the future of LLMs and AI Agents, and learn what the general availability of SharePoint Embedded means for enterprises.

Explore the possibilities of Microsoft Teams custom development and learn how to create new apps for your teams.

Avenga, a global engineering and consulting platform, announced today that Ludovic Gaudé has been appointed as its new CEO.

Unleash the power of insights-driven marketing by learning about the revolutionary Salesforce and AI toolkit that literally reinvents the value of data for efficient marketing.

Learn how to optimize your Microsoft 365 investment and select the proper licenses for your organization.
* US and Canada, exceptions apply
Ready to innovate your business?
We are! Let’s kick-off our journey to success!