






Running Kubernetes On-Premises Versus in the Cloud


June 18, 2025 10 min read 134 views
Is running on-premises Kubernetes clusters worth the effort?
Kubernetes (K8s), an orchestration tool for container-based workload management, is being rapidly adopted by organizations seeking to deploy and run microservices-based applications at scale. It helps them deliver quality digital products and services fast. No wonder that by the end of 2022, more than 60% of organizations have already adopted Kubernetes clusters (Fig. 1).
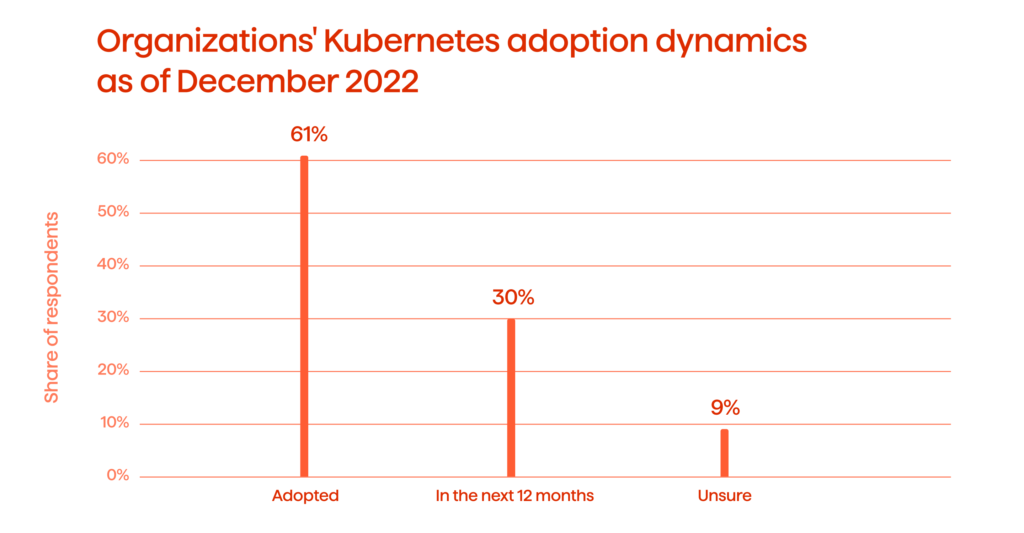
K8s allows IT organizations to become more responsive to their business needs, gives engineers instant access to resources, and provides operators with a way to manage multi-cloud operations seamlessly. Traditionally though, it is only thought of as a cloud-native platform.
But what if the cloud is not an option?
Whether out of fear of data breaches or for whatever other reason, some organizations choose to run clusters on their on-premises infrastructure. So, should they stick to virtual machines (VMs) and forget about the scalability, availability, and flexibility that containers and Kubernetes can offer?
Luckily, they don’t have to. Kubernetes on-premises deployments, while being tricky to implement, can still provide considerable benefits to the business if managed properly. In this article, we’ll explain the key differences between running K8s in the cloud and on-prem and share some of the best practices we use at Avenga to make on-prem Kubernetes deployments work flawlessly.
What Does Kubernetes Do?
K8s is an open-source, portable, and extensible container orchestration platform that helps automate app deployment and management, run distributed systems resiliently and scale them quickly in response to load. In layman’s terms, Kubernetes ensures all your containers are in the right place, interacting with each other.
What Constitutes a Kubernetes Architecture?
Each K8s cluster is made up of master nodes (collectively called a Control Plane) and worker nodes. Master nodes are responsible for cluster management, and they run four important processes:
API server. This element decides whether to let updates, applications, or new pods into the cluster. It also ensures that only authenticated queries can get through. Since there might be multiple master nodes, API servers must be load-balanced.
- Scheduler. After receiving a request from the API server, this process evaluates resource availability and chooses which node is the best candidate for hosting the new pod or application. Then, it hands the request over to Kubelet, which carries out the scheduling.
- Controller manager. The CM monitors the cluster status and detects pod crashes. It also tells the scheduler when to restart the dead pods.
- etcd. This element stores the cluster status information that the other three processes rely upon when performing their respective tasks. Much like the API server, etcd is distributed between the master nodes.
Each worker node hosts a bunch of pods – the smallest deployable computing units in Kubernetes. These pods are comprised of one or several containers, which share resources and storage. Worker nodes have their own set of processes:
- Container runtime – the component is responsible for running containers on the host operating system (OS).
- Kubelet – this is the K8s process that talks both to the container runtime and the node itself. Kubelet is responsible for starting the pod and assigning resources, like CPU, RAM, and storage, from the node to each container.
- Kube proxy. This process forwards requests to the appropriate pod using its built-in forwarding logic, which reduces overhead and boosts communication efficiency.
Why Is Running On-Prem Kubernetes So Much Harder?
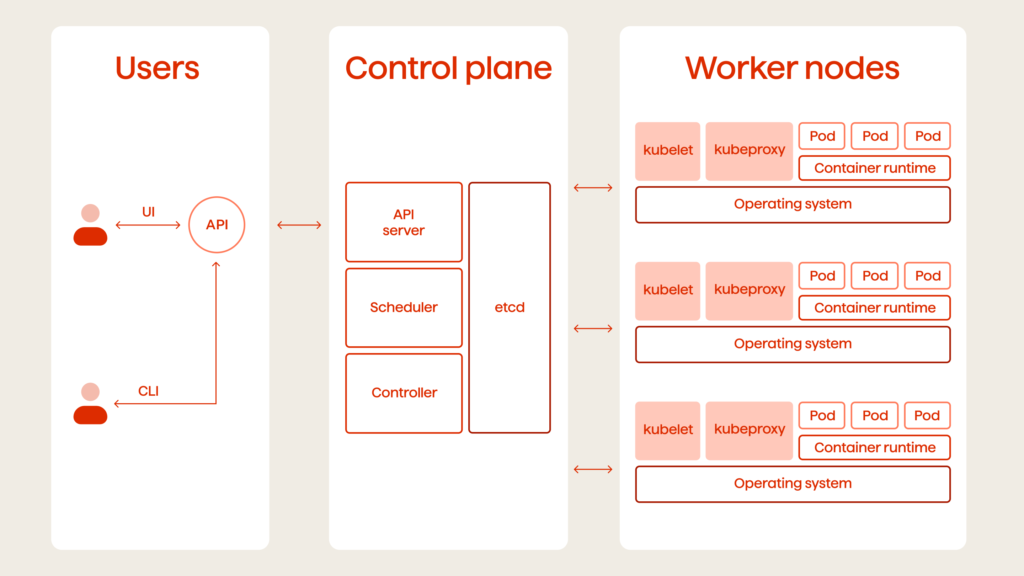
As you can see, the K8s’ architecture is quite simple, especially when you compare it to Openstack (Fig. 2). But it will become overwhelmingly complex once you take away the cloud services.
With them gone, you’ll suddenly have to worry about authentication, overlay networking, provisioning, a load balancer in front of the API server, multi-node clustering, transport layer security, and much more. And it is the lack of automation around this functionality that can make your on-prem deployment fall flat on its face.
To make an on-prem Kubernetes deployment work, your engineers must set all these things up and figure out a way to map them into the existing infrastructure. In addition, they have to adapt the standard instructions because, for Kubernetes, many of those elements are required.
So, are on-prem Kubernetes deployments still worth a try?
Reasons Not to Use the Cloud
Besides superstition, a general distrust of the cloud, and resistance to change, some organizations have rational reasons to avoid it. For example:
- Their on-prem infrastructure is working great, so they see no point in replacing it or carrying out a long and costly data migration.
- They rely on a hybrid cloud setting in which the workloads are run from an on-prem data center, and this approach suits their business policies perfectly.
- They work with data that is just too sensitive for any public cloud.
- The costs of running a data-intensive piece of software in the cloud are too high for them.
The CNCF’s Cloud Native Survey 2021 states that 22% of users run on-prem Kubernetes deployments.
Requirements and Considerations for On-Prem
Load Balancer
The first thing to consider when building any infrastructure is a load balancer. It’s an essential element both for the API server and the applications. While K8s does distribute the load and directs incoming traffic, it only provides one Ingress point which won’t be sufficient in most cases.
Ingress is an API object that manages external access to the services in your cluster. (Fig. 3).
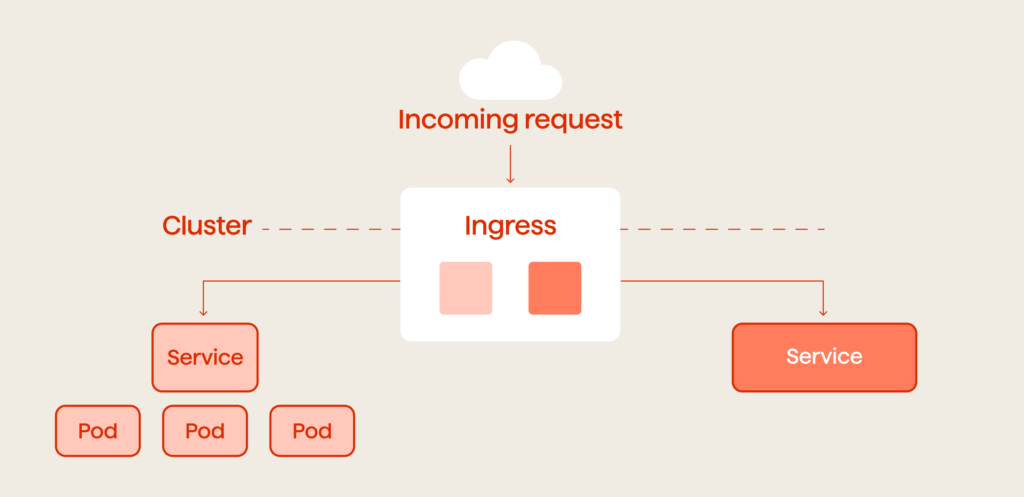
Your load balancer must also be dynamic.
Unlike some static web server farms, an on-premises Kubernetes cluster will grow and change over time. Therefore, you will need constant updates on the system’s overall health. There are a few ways to go about this:
- Using MetalLB, a load balancer implementation designed specifically for on-prem Kubernetes clusters. It leverages standard routing protocols and integrates easily with network equipment.
- Adding an external load balancer, in which case you’ll have to figure out how to connect it to the existing infrastructure on your own.
- Using a service mesh, an infrastructure layer that addresses all the challenges related to load balancing, discovery, failure recovery, and system monitoring.
Networking
K8s makes a lot of networking assumptions which limits your networking choices. As a result of this, setting up proper traffic segmentation can be extremely difficult. You will also have to find a way to keep preventing Docker from taking over your networking.
Consider using VMs for this – you can put multiple NICs (network interface controllers) into each of them, and it doesn’t take much effort to assign a VM to the network of your choice. Also, they can be extremely helpful in terms of container isolation.
Besides that, CMI plugins like WeaveNet, Calico, and Flannel could also be of great use. You might even think about investing in some extensions to get visibility and valuable insights from them.
Note that if your networking requirements are exceptionally complex, you might be better off not using K8s and containers at all.
Updates
When running an on-prem K8s cluster, organizations should plan for the continuous deployment of their infrastructure and think through how they will keep updating the dependency graph beneath it.
It is important to incorporate K8s’ quarterly update releases, which include bug fixes, security patches, etc., as well as to monitor the release cycles and versioning of all the elements around the infrastructure, such as OS, Docker, and various networking pieces.
Avoid building automation that has no upgrade path.
For some, it’s better to start with multiple small clusters and run them on different versions. While this approach seems difficult and might present certain challenges in terms of management, it will also minimize the blast radius.
Start small, think about the day two upgrades, and give yourself some time to devise a strategy for cluster convergence.
Storage
K8s is a perfect fit for stateless servers and applications that might or might not require scaling. In other cases, figuring out storage concerns will be hard.
One of the most viable options here is using ephemeral machines.
Docker images tend to accumulate quickly, so you’ll need to ensure you don’t run out of storage infrastructure unexpectedly. This can be achieved by keeping up a nice machine rotation hygiene, as well as expanding and contracting the cluster. Also, try attaching remote storage to your containers using stateful sets.
Remember that your networking infrastructure has to be built in a way that helps isolate storage traffic. You must make sure it won’t bog down when you attempt to carry out multiple storage operations at once.
OS and Host Provisioning
Since Docker and Containers are new, expect to be using the latest operating systems (kernels, drivers, etc.) when working with them. Unlike VMs, containers do not have the proper isolation, so it’s crucial that you build, maintain, and patch machines properly from the get-go and then keep monitoring the entire system closely.
Likewise, expect to be doing a lot of reprovisioning. K8s allow you to shut down and rotate machines through the cluster, so take advantage of that and make it a regular failure management practice. It would be wise to assume that your K8s cluster won’t be static and that you’ll just have to keep running machines in an upgrade pattern through the system.
If you’re using a distro, you’ll need to consult its requirements.
Additional Tips
- Use at least three servers for your K8s cluster to balance the workload and internal services.
- Make sure that the master components run separately from the containers.
- Run the kubeadm installation tool on the master.
- Set up three or more master nodes to ensure cluster availability and resilience.
- Allot three to seven 2GB RAM 8GB SSD nodes to Quorum; this is needed for recoverability.
- Only work with experts who are well-versed in troubleshooting and setting up load balancing. You don’t want to take any risks here.
In Conclusion
Using the cloud is clearly the easier choice when it comes to Kubernetes, but that doesn’t mean on-prem deployments aren’t worth the effort. If your organization is bound by security guidelines or has some other reasons to control the stack fully, K8s can still bring all the benefits of the cloud-native infrastructure if you run it on-prem. And, it doesn’t matter whether you use Openstack, VMware, or bare metal.
However, if you decide to use on-prem, you should know that Kubernetes alone, stripped of all the cloud services, won’t be able to support your application. You’ll need a plan on how to manage access control, load balancing, ingress, networking, provisioning, storage, and all the other vital infrastructure elements.
Start small, use VMs to run your clusters, and expect that getting the infrastructure to run smoothly will probably take some time. Additionally, plan for integration and assume you’ll have to do lots of operations work around your cluster.
Remember that Kubernetes isn’t a hammer that solves any problem. It’s not even that mature a technology yet, so be sure to use it the way it’s meant to be used, and you need some help with that, do not hesitate to contact us!


Your ultimate Salesforce audit guide

Types of cloud migration: advantages and disadvantages
Your business results matter
Achieve them with minimized risk through our bespoke innovation capabilities. Fill in the form below.