






Generative AI in pharma and life sciences industry: A comprehensive guide


June 5, 2026 12 min read 135 views
The pharma industry is on the brink of a significant transformation. Generative AI tools are accelerating the most challenging aspects of the work. Consider all the hours spent searching for data, gathering evidence, drafting documents, and making revisions. AI streamlines all of that. Suddenly, companies can advance more quickly in drug discovery and development, make better decisions, and avoid wasting time on manual reviews.
What’s truly remarkable is how AI connects raw data to concrete action. In discovery, it enables scientists to generate new ideas, evaluate targets, and select the most promising candidates, all much faster than before. During development, teams can handle protocols, eligibility checks, site planning, and patient materials without unnecessary delays. The real advantage is about building tighter feedback loops so teams can learn continuously and make more confident decisions.
This article explains how leaders can monitor achievements without sacrificing compliance or scientific integrity, how to make influence tangible, and what enables generative AI in life sciences adoption at scale.
AI in the pharmaceutical industry: key takeaways
- Generative AI in life sciences capabilities are greatest where pharmaceutical teams invest time sifting through, synthesizing, and iterating on evidence-rich workflows.
- The primary actionable uses of AI span drug discovery acceleration, optimizing clinical trials, and speedier medical literature analysis.
- The impact of AI is influenced by the quality, provenance, and assessment of the data so that the results can be sustained during the regulatory review process.
- Governance defines the criteria for success in adopting (at scale) AI that address responsible use, reduce bias, and protect intellectual property/privacy.
The generative AI opportunity across the pharma value chain
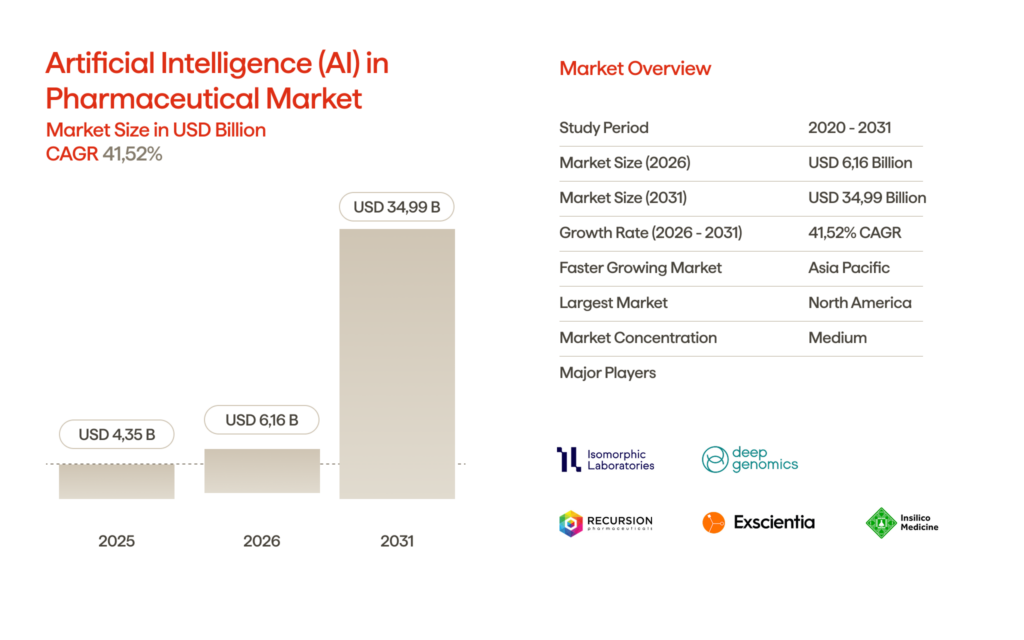
A market estimate puts generative AI models in pharma at about $4.16 billion in 2026, with a massive jump to nearly $35 billion by 2031. That’s about 41.5% CAGR from 2026 to 2031. Pharma teams are feeling the heat to move faster, reduce failure rates, and build evidence much more efficiently across R&D, clinical, and medical. Generative AI has the chance to change the game here. It speeds up those “knowledge-to-decision” cycles, especially in places where people spend ages searching, piecing together, and reworking complex data. That’s where the industry sees the real upside.
Use case 1: drug discovery acceleration and molecule design
Generative models are transforming drug discovery. They generate novel molecules, modify existing ones, and explore chemical space much more rapidly than traditional approaches. Here’s how it works: AI capabilities create lists of potential structures, small molecules, new modalities, whatever is needed, then filter them using property predictors and simulation tools to evaluate things like potency, selectivity, and developability. Of course, laboratory experiments are still necessary to verify results, but this strategy allows researchers to enter the lab with better hypotheses, reducing the number of trial-and-error cycles.
Active learning combined with generative design often allows teams to advance faster. After obtaining assay results, the data are reintroduced into the model to refine the focus of subsequent experiments on the highest-potential candidates. Much of the advantage of this process can be realised early: selecting the best compounds to advance, optimising lead candidates, and designing near-neighbours that maintain effective activity while remaining within acceptable ADMET ranges. It’s a more efficient and intelligent way to navigate the challenging initial stages of drug design.
Proof that the future is already here
Real-world approvals are now validating what was once theoretical. In January 2026, Insilico Medicine received an Investigational New Drug (IND) approval from the FDA for ISM8969, an orally available NLRP3 inhibitor intended for the treatment of Parkinson’s disease. The drug was discovered and optimised using Insilico’s Chemistry42, a generative chemistry engine that spans multiple drug design and discovery stages. A key factor in its approval was the molecule’s ability to cross the blood-brain barrier, a challenge that has historically limited the effectiveness of many neurological treatments.
This is not an isolated case. Rentosertib, a first-in-class AI-generated small-molecule inhibitor, became the subject of the first Phase IIa trial testing the safety and efficacy of a generative AI-designed drug, with results published in Nature Medicine in 2025. While no AI-discovered drug has yet achieved full FDA approval, AI has proven it can compress early-stage discovery timelines by 30 to 40% and reduce preclinical candidate development to 13 to 18 months, compared to the traditional three to four years.
The FDA approving an IND for an AI-designed molecule targeting neurodegeneration signals a clear shift. Generative AI is no longer running simulations in a lab sandbox. It is putting drugs into human trials.
Use case 2: clinical trial optimization and patient recruitment
Trials run on data. Generative AI solutions step in to draft and review protocol language, flag feasibility risks, and ensure eligibility criteria are consistent across sites. For recruitment, AI lines up those inclusion and exclusion rules with real patient records, finds promising matches, and helps create outreach materials people actually understand. These tools make a difference. Late starts compound problems: slow enrollment leads to missed milestones, and poor protocols force teams to start over on their work. However, when used effectively, generative AI can accelerate document review and help develop more targeted screening methods for everyone involved. In the end, it’s still up to the people to make the final decision.
Use case 3: medical literature analysis and synthesis
Medical teams spend hours sifting through publications, abstracts, safety reports, and various internal documents to extract just a handful of clear insights. Generative AI technologies transform this process. They can scan vast amounts of data, identify the key endpoints, and organize evidence by patient population or comparator. It even assembles initial drafts for internal briefs, medical information responses, and evidence dossiers. This is exactly where the technology excels right now: less time spent wading through endless paperwork, faster results, and outputs that remain consistent, as long as the AI’s answers are anchored to the sources and thoroughly verified for accuracy.
Leverage cutting-edge tools to streamline and automate clinical trial processes.
Data quality and training considerations for pharma companies
The introduction of generative artificial intelligence (AI) into R&D teams is changing how these organisations search for, synthesise, and iterate through their R&D projects. Pharmaceutical companies can achieve the maximum value from generative AI when they treat the data layers in their work as regulated infrastructures. In drug discovery, poor-quality inputs yield outputs that appear valid during review but are ultimately rejected. Additionally, the risk of rejection increases when training AI algorithms on data sources with mixed quality and without adequate provenance.
If companies want traceable, reproducible results, they need to put real effort into their data practices. It starts with careful curation, using standard vocabularies and ontologies, keeping compound and target identifiers consistent, removing duplicates, normalizing units, and ensuring every experimental condition is clearly labeled. But that’s just the beginning. Good governance matters just as much. You have to know where every piece of data comes from, track what changes, and control who can access sensitive information.
When it comes to training, there’s no room for compromise on privacy: data has to be de-identified and protected. And for evaluation, the process needs to match real-world workflows—get subject matter experts to review, break down errors into specific types, and really push the system to catch any hallucinations. That’s how you build reliable data pipelines.
The most commonly used options for “teaching” a model include retrieval-based grounding, fine-tuning, and hybrid approaches between the two extremes. The final decision will be driven by the required update frequency, regulatory requirements for traceability, and the organisation’s tolerance for model drift.
| Approach | What it uses | Strengths | Key risks | Best fit |
| Grounding (RAG) | Curated knowledge base + citations | Traceable outputs, easier updates | Bad retrieval = bad answers; needs strong indexing | Literature synthesis, medical info, internal Q&A |
| Fine-tuning | Labeled domain examples | Style/format control, task specialization | Harder to audit sources; drift and bias risk | Structured extraction, classification, drafting templates |
| Hybrid (RAG + tuning) | Both retrieval and tuned behavior | Strong accuracy + usability | More moving parts to govern | High-stakes workflows with strict QA |
| Domain adapters (LoRA) | Smaller domain-specific layers | Faster iteration, lower cost | Still needs robust evaluation | Rapid pilots with controlled scope |
Ethical considerations and bias mitigation in AI use
The ethics of pharma AI projects determine whether they will gain public trust. For a generative AI project to benefit patients, it must be backed by sound scientific evidence, approved by reliable regulatory agencies, and given ample opportunity to be vetted through empirical evidence in the real world.
Patient safety and reliability come first
In the pharmaceutical industry, a large portion of generative AI capabilities works as ‘knowledge accelerators’ (eg, summarising evidence, drafting protocols, synthesising safety narratives). A significant issue with language models is their ability to produce confident errors (oriented). They often fail to include appropriate context and/or invent citations. WHO’s guidance on AI in Health stresses that safety, accountability, transparency, and human oversight must be built in from the outset and not added post-processing. Additionally, real-world evidence on safety reporting across AI-enabled medical technologies underscores the importance of proper governance when systems influence clinical decision-making.
Businesses should have citation verification, an SME review process, grounding of all source documents, and a stop condition for all high-impact deliverables (anything that could affect patient safety, labeling, or regulatory submissions).
Bias can hide in data and in workflows
Bias creeps in when the training data doesn’t really match the people it’s supposed to represent. Say the labels carry over old gaps in healthcare access, or the model just works for the “usual” group and stumbles when faced with anyone different—that’s when problems show up. The National Institute of Standards and Technology (NIST) AI Risk Management Framework notes that you need to track and address these harmful biases at every stage, not just run a single fairness check and call it good.
Practical mitigation for AI adoption:
- Evaluate performance by subgroup (age, sex, geography, site type) and document trade-offs.
- Use representative datasets or reweighting strategies where feasible.
- Monitor drift post-deployment and retrain with controlled change management.
Transparency, human oversight, and auditability
Good governance is what separates successful organizations from those that go beyond the pilot phase. The EU’s AI Act lays down clear rules for high-risk systems, demanding transparency and real human oversight. In regulated medical settings, the FDA’s Good Machine Learning Practice Guidelines push this even further, locking in strict lifecycle controls and keeping the focus on user-centered information.
Controls that make the benefits of generative AI repeatable:
- Model/data documentation (datasets, intended use, limits, known failure modes)
- Approval workflows for model updates, with regression testing and audit logs
- Human-in-the-loop decisioning for anything safety- or compliance-relevant
Privacy and IP considerations
Pharmaceutical-related information is considered sensitive, as it is typically included in clinical trial documents. Sensitive information usually consists of personally identifiable information (PII), proprietary information, and other materials that may also appear in real-world evidence (RWE), safety case narratives, and pharmaceutical manufacturing documentation. The majority of privacy risks occur when teams move at higher velocity and use data from other projects without sufficiently clear/reasonable guidelines on use, consent, or retention.
A practical baseline would be to limit what is ingested into the model layer; de-identify (or, at a minimum, pseudo-anonymize), where appropriate; and implement robust access controls, audit logs, and data residency controls on all environments that interact with patient data. Many teams distinguish “knowledge access” and “model training” by creating a separate private retrieval system for accessing internal documents and by limiting fine-tuning of their training parameters to the most tightly governed corpora to ensure data privacy and security.
IP risk isn’t like other threats, but it’s equally serious. If you train on licensed material without the proper permissions, incorporate trade secrets into prompts, or let confidential R&D information appear in generated results, you’re giving competitors an edge. Companies need to be precise, create clear guidelines for data licensing, secure solid vendor contracts, and determine how to manage model outputs. Technical protections are essential as well. Use DLP filters, redaction solutions, and restrict context windows when handling sensitive information.
FAQ
Making adoption measurable and safe in drug development
Pharma executives who regard AI systems as a strategic operational tool will reap the most significant benefits from this technology. Generative AI enables pharma organizations to narrow the gap between evidence and action across the entire drug development lifecycle, from discovery to clinical trials to regulatory approval, by ensuring that all outputs can be tracked and evaluated.
Want to learn more about how AI is transforming the pharmaceutical industry? Contact Avenga, and discover the full potential of AI.



Your business results matter
Achieve them with minimized risk through our bespoke innovation capabilities. Fill in the form below.