

Avenga uznana za czołową firmę w dziedzinie rozwoju AI w 2024 roku w rankingu Techreviewer
Dowiedz się dlaczego Techreview wyróżnił Avenga jako jedną z najlepszych firm w dziedzinie AI w 2024.

Analityka danych prowadzona w odpowiedni sposób może przynieść przełom w analityce biznesowej.
Według Allied Market Research, rynek przetwarzania danych przeżywa rozkwit i cieszy się ogromnym zainteresowaniem. Obecna wartość tego rynku to 650 mln USD i szacuje się, że do 2031 r. wzrośnie ona do poziomu 5 mld USD. Dlatego tak dużo pisze się na temat obsługi danych z wykorzystaniem różnych platform programistycznych. Aby lepiej zrozumieć ten fenomen, przyjrzyjmy się kilku pomysłom i potwierdzonym w praktyce przykładom przetwarzania danych.
Krótko mówiąc, istnieje wiele przykładów klientów, którzy chcą zbudować lub uporządkować swoje ekosystemy danych. Tego typu procesy obejmują monitorowanie wykorzystania danych przez użytkowników biznesowych, co jest możliwe dzięki raportom lub bezpośredniemu dostępowi do danych. I szczerze mówiąc, nie można zrobić tego źle. Istnieją jednak sytuacje, w których na początku projektu może on obejmować tylko niektóre przypadki użycia i podstawowe wymagania architektury, kluczowe w procesie tworzenia ekosystemu danych spełniającego oczekiwania klienta.
Z naszego doświadczenia wynika, że budowanie platform do analizy danych z zastosowaniem rozwiązań chmurowych jest bardzo efektywne. Wykorzystuje się w nich sztuczną inteligencję (AI) i uczenie maszynowe (ML). Dzisiaj opiszemy, w jaki sposób platforma Azure Data Platform może spełniać oczekiwania klientów.
Podczas korzystania z wybranej platformy napotkaliśmy dwa problemy:
Wymagań co do systemu nie było zbyt wiele, jednak musieliśmy wziąć pod uwagę kilka najistotniejszych kwestii:
Biorąc pod uwagę powyższe oczekiwania, w naszym projekcie musieliśmy skupić się na przechowywaniu danych i połączeniu JIRA z GitHub. Te dwa aspekty okazały się mieć kluczowe znaczenie dla wybranych możliwości przetwarzania danych. Aby jednak uzyskać jaśniejszy obraz sytuacji, trzeba poznać pewien istotny kontekst.
Najważniejszą kwestią było zorganizowanie przechowywania danych. Nasze wcześniejsze doświadczenia wskazywały, że możemy użyć kolumnowego magazynu RDBMS do przechowywania danych w fazie przejściowej. Następnie moglibyśmy je przekształcić i ustrukturyzować. Istnieje wiele nowych typów danych, np. JSON czy pliki blob, jednak klasyczny RDBMS musi spełniać ważne wymagania architektury systemowej. Ostatecznie uznaliśmy, że RDBMS nie będzie optymalnym rozwiązaniem do przechowywania tego typu danych.
PostgreSQL oferuje szereg przydatnych funkcji, gdy w grę wchodzi zarządzanie plikami JSON. Na to chcieliśmy zwrócić tu uwagę. Ten silnik bazodanowy byłby także właściwym wyborem, jeśli inne typy danych byłyby niedostępne. W naszym przypadku musieliśmy zadbać o przechowywanie plików typu blob (grafiki, wideo z Twittera itp.). Jednym z najistotniejszych wymagań było wykorzystanie platformy Azure, ponieważ oferuje ona pamięć masową typu blob, w której mogliśmy przechowywać nasze dane. Z tą pamięcią mogliśmy zintegrować wiele innych usług. Okazało się to pomocne w wyszukiwaniu tych danych za pomocą SQL (Structured Query Language) ze specjalnymi usługami. Na tym etapie potrzebowaliśmy odpowiedniego inżyniera danych, który mógłby wykorzystać ekosystemy Synapse i Databricks do rozwiązania wspomnianych wcześniej problemów.
Azure funkcjonuje na bazie ekosystemu danych w chmurze. Ten system to Synapse Analytics, który obejmuje następujące elementy:
Na platformie Azure dostępne są także inne usługi. Mamy do wyboru np. platformę Analysis Services, AI\ML i Power BI (Business Intelligence). Można tu dodawać różne funkcje Azure, aplikacje logiczne itp., aby spełniać swoje wymagania. My mogliśmy akurat z łatwością powtórzyć zabiegi mające na celu wdrożenie systemu analitycznego na Synapse z naszego poprzedniego projektu. Za pomocą Data Factory połączyliśmy ponad 10 źródeł danych. Następnie załadowaliśmy je do jeziora danych. Potem wyodrębniliśmy dane zapytań z tabel w dedykowanej lub bezserwerowej puli SQL za pomocą SQL; dedykowana pula SQL zawiera statyczne tabele w warstwie nieprzetworzonej, podczas gdy bezserwerowa ankieta SQL zawiera tabele zewnętrzne. Daje to możliwość odpytywania danych za pośrednictwem studia zarządzania lub dostawcy danych OLEDB (było to jednym z wymagań).
Korzystanie z Azure Synapse Analytics zapewnia nam najniższy koszt niezbędnych usług. Co więcej, mamy do dyspozycji moc dedykowanej puli SQL ze wszystkimi funkcjami Azure DWH. Oznacza to również, że można wstrzymać tę usługę i uruchomić ją ponownie zależnie od potrzeb. Nie będziemy jednak rozpisywać się tu na temat wszystkich zalet tych usług; komplet niezbędnych informacji można znaleźć w dokumentacji Microsoft.
Wracając do naszego projektu, oto jedna z architektur referencyjnych opartych na ekosystemie Azure Data. (patrz rys.1).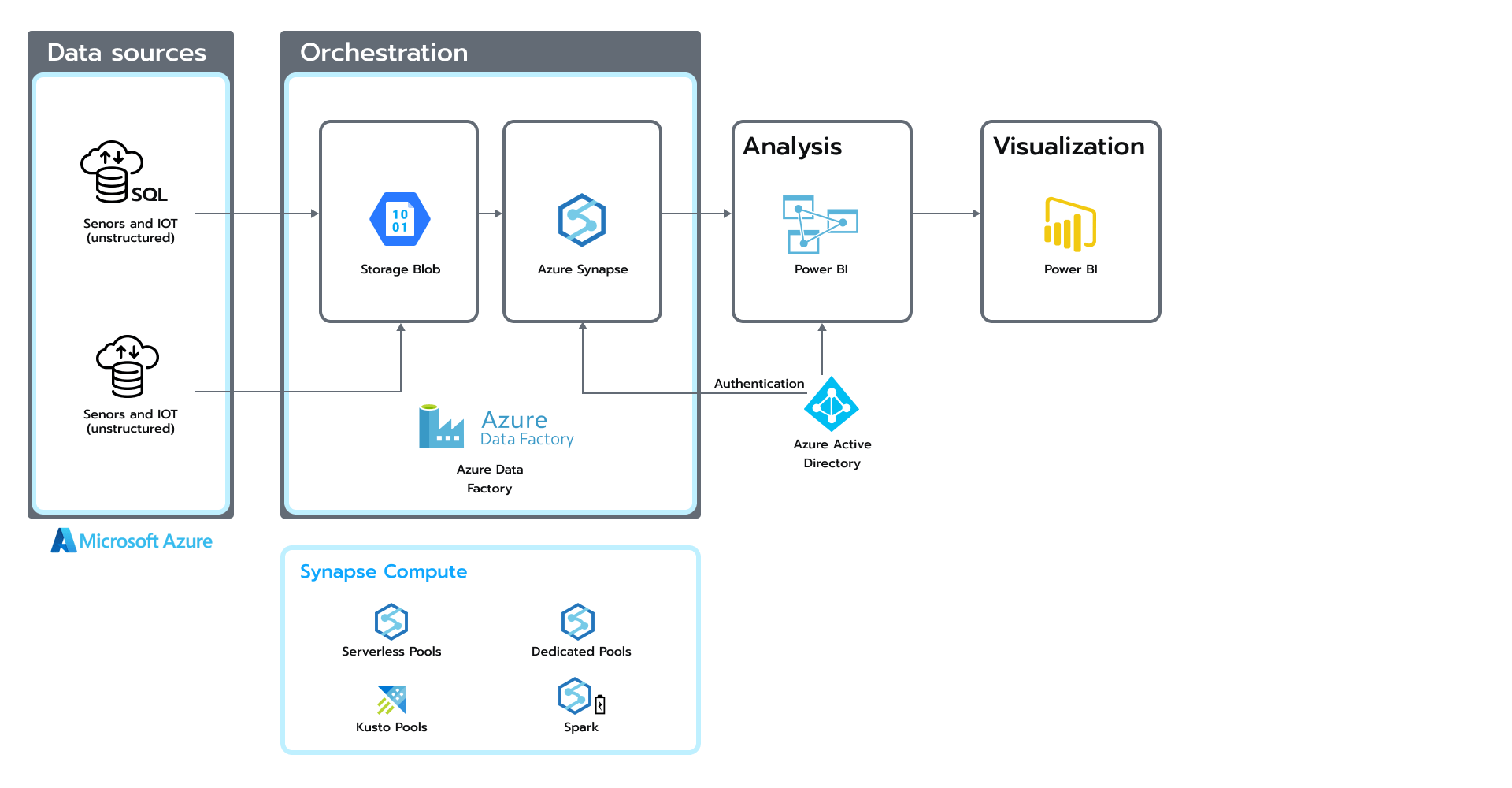 Rysunek 1. Architektura oparta na ekosystemie Azure Data
Rysunek 1. Architektura oparta na ekosystemie Azure Data
Powyższy rysunek przedstawia cały proces — od ekstrakcji danych ze źródeł po orkiestrację, analizę i wizualizację. W ramach opracowanego rozwiązania zastosowaliśmy ekosystem Databricks.
Ekosystem Databricks zapewnia ujednolicony zestaw narzędzi dla inżynierów i analityków danych. Pomaga tworzyć potoki danych i uczenia maszynowego. Narzędzie to umożliwia programistom wykonywanie różnych poleceń Spark w wygodnym formacie przypominającym notatnik. Architektura platformy Databricks składa się z dwóch podstawowych elementów:
Dlatego pakiet Databricks jest w stanie działać z każdą usługą chmurową. Rozwiązanie to umożliwia też pełniejszą integrację systemu z innymi usługami w chmurze. Na przykład w omawianym projekcie połączyliśmy notatniki Databricks z innymi usługami Azure, takimi jak Data Factory, ADLS, Azure Monitor, Event Hubs i Active Directory.
Ponadto usługa Azure oferuje prosty interfejs użytkownika, dzięki czemu jesteśmy w stanie łatwo wybrać najlepszy typ klastra dla różnych obciążeń. Oprócz potoków danych nasz zespół wdrożył też kilka notatników uczenia maszynowego. Zespół data science wykorzystał wbudowane API biblioteki pandas w Spark, które automatycznie konwertuje polecenia pandas na analogi Spark.
W zależności od typu obciążenia, zespół może przyjrzeć się klastrom zoptymalizowanym pod kątem pamięci dla konwersji wymagających dużej ilości pamięci lub klastrom uczenia maszynowego z zainstalowanymi dodatkowymi bibliotekami uczenia maszynowego. Integracja GPU lub krótkoterminowe klastry zadań to optymalne rozwiązania, gdy priorytetem są oszczędności kosztów. Databricks to narzędzie, które zarządza infrastrukturą chmury i wdraża ją w swoim imieniu.
Aby zbudować nowoczesne jezioro danych, nasz zespół przyjął podejście zwane lakehouse (repozytorium danych). Dane zostały podzielone na trzy warstwy według formatu i zastosowanej konwersji.
Warstwy srebrna i złota korzystały z biblioteki open-source’owej Delta Lake. W rezultacie otrzymaliśmy efektywną strukturę dla zapytań ad-hoc i na potrzeby raportowania. Delta Lake stworzone na bazie innego formatu open-source’owego Parquet, daje użytkownikowi do dyspozycji zaawansowane funkcje, które przekładają się na solidną strukturę, szybkość działania, możliwość wersjonowania i zgodność bazy z założeniami ACID (atomowość, spójność, izolacja i trwałość).
W efekcie nasz zespół stworzył niedrogie rozwiązanie, w którym pamięć masowa w całości opierała się na usłudze Azure Data Lake Gen2. Udało nam się również ograniczyć koszt mocy obliczeniowej zatrzymując klastry deweloperskie i wykorzystując klastry zadań do zaplanowanych obciążeń ETL (wyodrębniania, przekształcania i ładowania).
Dowiedz się, jak opracowaliśmy rozwiązania do przetwarzania danych, pozwalając naszym klientom na lepsze zrozumienie ich klientów. Ayasdi: Uczenie maszynowe w służbie przetwarzania danych
Naszym początkowym celem było połączenie ze sobą dwóch źródeł danych JIRA i GitHub, po to by stworzyć jezioro danych. Następnie przekształcone dane będą wykorzystane do opracowania raportów pokazujących zależność między pracą programistów w GitHub a zamkniętymi zgłoszeniami w JIRA; kierownik projektu zobaczy dane dotyczące efektywności zespołu. Po zakończeniu tego etapu prac, kilkakrotnie rozszerzyliśmy zakres źródeł danych:
Po pierwsze, podpięliśmy GitLab jako dodatkowe źródło do GitHub, ponieważ niektóre projekty przechowują tam kod, co dało nam możliwość podłączenia większej liczby projektów do pulpitu nawigacyjnego.
Po drugie, połączyliśmy źródła społecznościowe Twitter i Telegram. Były one potrzebne do uzyskania informacji niezbędnych do opracowania interaktywnej mapy, wyświetlającej wiadomości z ich geograficznymi lokalizacjami. W tym celu skorzystaliśmy z NLP (przetwarzanie języka naturalnego), aby rozpoznać nazwę miasta, gdy jest wspominana, i przypisać ją do właściwej lokalizacji geograficznej. Użyliśmy również automatycznego ładowania i przesyłania strumieniowego Databricks, aby skrócić czas, po którym dane są dostępne do analizy.
Zbudowaliśmy czterowarstwowe jezioro danych do przechowywania danych surowych i przetworzonych: nieprzetworzonych (Raw), wzbogaconych (Cleansed), nadzorowanych (Curated) i laboratoryjnych (Laboratory). Laboratorium to dodatkowa warstwa, która łączy elementy z pierwszych trzech warstw. Jest wykorzystywana do autoanalizy i uczenia maszynowego. Dla tej warstwy nie przyjęto żadnych konkretnych reguł, ponieważ dane są przechowywane w różnych formatach w zależności od potrzeb biznesowych.
Podczas prac nad rozwiązaniem stosowaliśmy różne podejścia do przechowywania i przetwarzania danych w jeziorze danych. Kierowaliśmy się następującymi założeniami:
Do logiki transformacji użyliśmy notatników Python i uruchomiliśmy je na klastrze Databricks. Aby śledzić wykonanie wszystkich notatników, podpięliśmy monitor Azure, w którym przechowywaliśmy wszystkie niestandardowe powiadomienia. Mieliśmy notatnik przeznaczony do zapisywania logów, których ponownie używaliśmy w innych miejscach. Do orkiestracji korzystaliśmy z Data Factory. Aby na koniec sprawdzić, czy opracowane procesy przebiegają poprawnie i czy nie występują w nich nieudane wykonania, połączyliśmy Power BI bezpośrednio z Azure Monitor i utworzyliśmy pulpit, na którym mieliśmy podgląd stanu systemu. Wykorzystaliśmy też platformę MLFlow do monitorowania wskaźników wydajności procesów uczenia maszynowego i wersjonowania modeli.
Jakie były efekty naszej pracy? Aby osiągnąć założony cel, potrzebowaliśmy tych wszystkich ustalonych wcześniej reguł i dobrego systemu monitoringu. Na koniec podłączyliśmy do naszego systemu Power BI, aby zwizualizować połączenie między JIRA i Github (patrz rys. 2).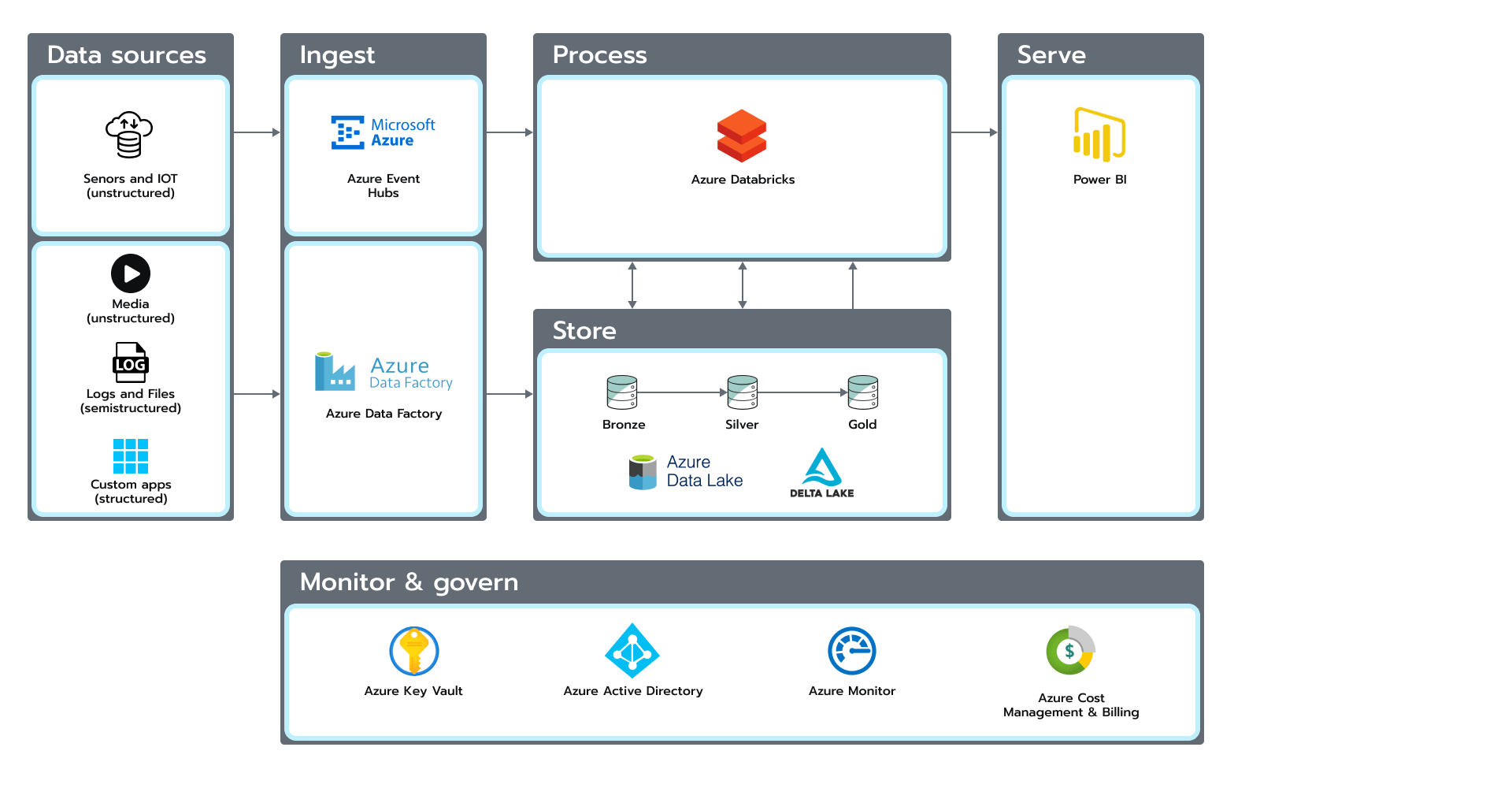 Rysunek 2. Połączenie JIRA i Github
Rysunek 2. Połączenie JIRA i Github
W ramach drugiej iteracji podłączyliśmy do naszego rozwiązania sieci społecznościowe. Następnie pobraliśmy nieprzetworzone informacje i zapisaliśmy je w warstwie nieprzetworzonej (Raw) naszej architektury. Później przekształciliśmy te dane i zapisaliśmy w warstwie nadzorowanej (Curated). Pomiędzy tymi procesami stosowaliśmy NLP, aby móc określić geolokalizację zapisaną w wiadomości i poszerzyć nasz model danych o atrybuty współrzędnych geograficznych. Na koniec użyliśmy mapy, aby wyświetlić wiadomości i wzmianki historyczne w określonym regionie zidentyfikowanego kraju. Efekty możesz zobaczyć tutaj.
Na pierwszy rzut oka realizacja powyższego projektu może wydawać się prostym zadaniem. Jednak osiągnięcie opisanych wyżej rezultatów jest możliwe tylko dzięki zastosowaniu odpowiedniej architektury. Opracowane rozwiązanie można rozbudować tak, aby spełniało nowe potrzeby biznesowe, mimo że każdy nowy przypadek będzie wiązał się z określonymi wymaganiami architektonicznymi, przypadkami użycia i decyzjami. Nie da się stworzyć idealnego, uniwersalnego rozwiązania jednorazowego, ponieważ każde rozwiązanie ewoluuje i staje się doskonalsze po kilku iteracjach.
Chcesz dowiedzieć się, w jaki sposób dane, którymi dysponujesz, mogą pomóc twojej organizacji sprostać różnym wyzwaniom biznesowym? Nasi eksperci są gotowi udzielić ci odpowiedzi, których możesz potrzebować. Skontaktuj się z nami.

Dowiedz się dlaczego Techreview wyróżnił Avenga jako jedną z najlepszych firm w dziedzinie AI w 2024.

Dowiedz się, jak zoptymalizować inwestycję w platformę Microsoft 365 i wybrać odpowiednie licencje dla swojej organizacji.

Poznaj korzyści płynące z tworzenia oprogramowania na zamówienie w porównaniu z gotowymi rozwiązaniami oraz powody, dla których warto wybrać dedykowane oprogramowanie.

Poznaj podstawy zarządzania dokumentami w Microsoft 365. Odkryj możliwości płynące z integracji OneDrive for Business, SharePoint i Teams.

Zapewnij swoim pracownikom nowoczesne rozwiązania intranetowe. Odkryj podstawowe kryteria maksymalizacji zaangażowania, produktywności i współpracy pracowników.

Zapoznaj się z przewodnikiem po zasadach tworzenia spójnej strategii chmurowej. Dowiedz się więcej o zawiłościach związanych z wdrażaniem chmury.

Poznaj schemat oceny oprogramowania, który usprawni proces podejmowania decyzji. Jak mapę drogową do wdrożenia nowego oprogramowania trzymaj go zawsze pod ręką.

Odkryj nowe możliwości rozszerzenia intranetu opartego na platformie Microsoft 365. Przegląd najbardziej efektywnych rozwiązań.
* USA i Kanada, obowiązują wyjątki
Rozpocznij rozmowę
Chętnie odpowiemy na Twoje pytania. Skorzystaj z poniższego formularza, aby skontaktować się z nami. Odezwiemy się do Ciebie wkrótce.