






Stable Diffusion AI: how the AI image generator works and its business applications


July 30, 2026 11 min read 107 views
Generative models have advanced rapidly, with GANs (Generative Adversarial Networks) driving early progress in image and video generation, computer vision, and scientific research. More recently, computationally efficient diffusion models have expanded the possibilities of generative AI and accelerated the development of tools such as Stable Diffusion.
These advances are part of the broader evolution of artificial intelligence, where organizations combine large-scale data, Machine Learning models, and advanced algorithms to build new capabilities. In this article, we’ll explore how diffusion models work, how Stable Diffusion generates images from text prompts, and how these AI models have evolved from earlier generative approaches like GANs.
We created this image using Stable Diffusion
GANs, Diffusion, Stable Diffusion
AI image generation tools such as DALL-E, Stable Diffusion, and Imagen have become widely accessible, but the technology behind them remains complex. To understand how Stable Diffusion works, it is useful to examine the evolution from GANs to diffusion models and the image generation process behind them.
Generative algorithms contain many complex, interconnected components, even though generating images with Stable Diffusion may appear simple from the user’s perspective. Let’s look at these technologies one by one.
A GAN consists of two elements: a generator and a discriminator. The generator creates synthetic images and submits them to the discriminator, whose job is to determine whether they resemble real data. During training, the generator iteratively improves to produce more convincing outputs, while the discriminator adjusts its parameters to become better at identifying synthetic ones.
Eventually, the generator learns to create images that are convincing enough to fool even an advanced discriminator—and, in some cases, the human eye.

Video prediction is one of the most promising applications of GANs. By analyzing past frames, a network can predict what may happen in the immediate future, which has significant implications for modern surveillance systems and predictive maintenance platforms. GANs can also support image enhancement by analyzing and reconstructing individual pixels to generate higher-resolution images.
However, GANs also have important limitations. They are difficult and expensive to train and can suffer from mode collapse, in which the network repeatedly generates similar images. Their approach to transforming random noise directly into high-quality outputs can also produce visual artifacts and inconsistencies.
Diffusion models address some of these challenges by dividing the image generation process into smaller, repeatable stages. The process begins by gradually adding Gaussian noise to an image. More specifically, the model creates a Markov chain of timesteps in which the image moves from a clear state at t = 0 to nearly unrecognizable noise at t = T, the final step. The number of timesteps and the noise schedule are determined in advance and may range from hundreds to thousands of steps.
The model then learns to reverse this process. Instead of transforming complete noise into a finished image in one step, it learns to turn a noisy image into a slightly less noisy one, moving from one timestep to the previous one while learning the transitions between them. After training, the model can transform randomly sampled noise into a coherent image.

Diffusion models use an iterative denoising approach. At each timestep, the model estimates the noise in the current image, predicts a cleaner version, and then adjusts the result to continue the process at the next step. By repeatedly generating predictions from progressively less noisy inputs, the model can refine its output and correct earlier inaccuracies. This process provides the foundation for modern image generation models, including Stable Diffusion.
How does text guide Diffusion and Stable Diffusion?
To make image generation guided, Stable Diffusion first converts text prompts into vector representations called embeddings. These embeddings are then used to help the model understand the relationship between text and visual elements.
This is typically done with a GPT-style language model. The embeddings it produces are added to the visual input and fed to the diffusion model. Also, since diffusion models are mostly U-Net architectures, their cross-attention layers focus on individual text tokens produced by the transformer.
But that’s not all. We also use something known as classifier-free guidance to propagate the prompt further into the model. At each denoising step, the network produces two outputs: one with and one without access to the text. The difference between the results is then amplified and fed back, helping the algorithm follow the direction of the prompt more closely.
Diffusion vs. Stable Diffusion
Diffusion models provide the foundation for AI image generation, while Stable Diffusion is a specific open-source latent diffusion model created by Stability AI that makes high-resolution image synthesis more accessible.
Unlike many proprietary AI image generation models that are available only through APIs, Stable Diffusion can be downloaded, customized, and run locally to meet specific requirements. It also requires fewer computing resources than many earlier diffusion-based approaches.
Being from OpenAI, DALL-E 2 builds on many concepts and technologies that the firm had previously developed. For instance, it uses CLIP embeddings which convert text tokens into numbers.
The CLIP network is specifically trained on visual and text data pairs. Without delving into the math, let’s just say it learns to put the vector embeddings of an image and the corresponding caption close to each other in some space while ensuring a sizeable distance between unrelated pics and texts.
Diffusion models struggle to process large images, so they only work with small, typically 64×64 inputs, and then use upscaling mechanisms to get to the desired resolution. Both DALL-E and Google’s Imagen rely on this principle.
Stable Diffusion, however, has its own trick to deal with high dimensionality. Instead of working with images, its autoencoder element turns them into low-dimension representations. There’s still noise, timesteps, and prompts, but all the U-Net’s processing is done in a compressed latent space. Afterward, a decoder expands the representation back into a picture of the needed size.
How do video Diffusion models generate videos?
Stable Diffusion is based on diffusion models that can be extended beyond image generation to create AI art and video content by learning relationships between text, images, and motion. Video models build upon the same diffusion process used for image generation, adding components that help AI systems understand movement and temporal relationships.
This approach is evident in Meta AI’s Make-a-Video. The general idea is to take a trained diffusion model, which already knows how to associate text with visual content, and equip it with additional video processing capabilities. The model can also learn realistic motion from unlabeled video data collected from various sources.
The components of the network include:
- A base DALL-E-like diffusion model with a U-Net architecture that generates images from random noise. It includes a CLIP encoder that maps text prompts into a multimodal visual-language space and a prior network that converts this information into an image representation. Upscaling networks then improve the resolution of generated visuals.
- Additional layers that handle sequential data and temporal dimensions. These layers connect individual frames and help maintain consistency throughout the generated video.
- An interpolation network that increases the frame rate by generating additional frames and improving temporal coherence.
- Two spatial super-resolution models (SSMs) that gradually improve the resolution of each frame.
The Make-a-Video network is complex because different components are trained on different types of data. The prior and spatial super-resolution models are trained on images, the text-to-image diffusion model uses text-image pairs, and video-specific convolution and attention layers learn from unlabeled videos.
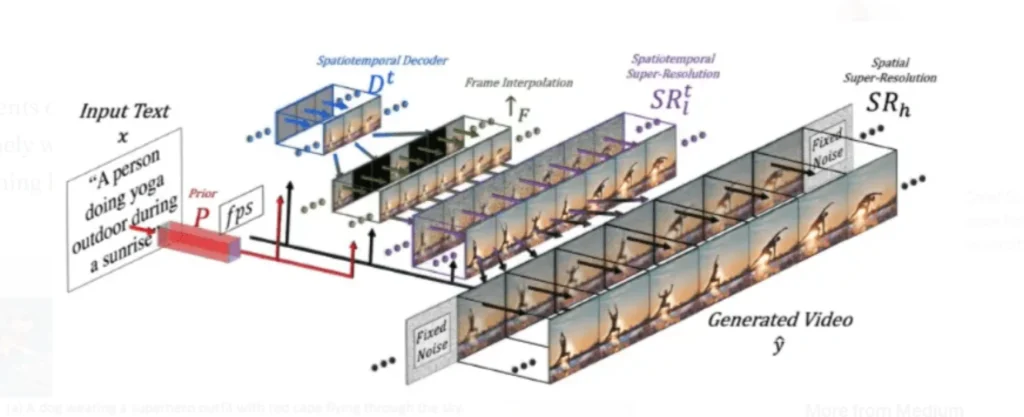
Imagen vs Make-a-Video: how do AI video models differ?
Imagen and Make-a-Video use similar diffusion-based architectures, but they differ in how they process text, image, and video data during training. In Imagen, the CLIP encoder and prior network are replaced with the T5-XXL transformer, which is trained on text only, unlike CLIP. The base diffusion model is also enhanced with additional convolution and attention layers, but its training is slightly different as it is shown in both image and video data simultaneously, and the model treats images as single-frame videos. This means video descriptions, which are hard to come by on the web, must also have been used and they’ve probably come from some internal Google-generated dataset. Next, we again have the supersampling network to get a higher framerate and the two SSR models. But then, Imagen goes further by adding two more upsampling models and yet another SSR.
Stable Diffusion applications
Stable Diffusion is a powerful AI generator based on latent text-to-image diffusion models that can create realistic visuals from text prompts and image inputs. Its capabilities go far beyond AI art, with use cases across industries that rely on high-resolution image synthesis, synthetic data generation, and visual content creation.
- 3D modeling. Google’s DreamFusion and NVIDIA’s Magic3D create high-resolution 3D meshes with colored textures from text prompts. With unique image conditioning and prompt-based editing capabilities, they can be used in video game design and CGI art creation (helping designers visualize, test, and develop concepts quicker), as well as manufacturing.
- Image processing. The applications here include super-resolution, image modification/enhancement, synthetic object generation, attribute manipulation, and component transformation.
- Healthcare. The models can help reduce the time and cost of early diagnosis while increasing its speed. In addition, they can significantly augment existing datasets by performing guided image synthesis, image-to-image translation, and upscaling.
- Biology. Stable Diffusion can assist biologists in identifying and creating novel and valuable protein sequences optimized for specific properties. The networks’ properties also make them great for biological data imaging, specifically for high-resolution cell microscopy imaging and morphological profiling.
- Remote sensing. SD can generate high-quality and high-resolution sensing, and satellite images. The networks’ ability to consistently output stable multispectral satellite images might have huge implications for remote sensing image creation, super-resolution, pan-sharpening, haze and cloud removal, and image restoration.
- Marketing. Stable Diffusion networks can create novel designs for promotional materials, logos, and content illustrations. These networks can quickly produce high-resolution and photo-realistic images that meet specific design requirements, and output a wide range of shapes, colors, sizes, and styles. In addition, the algorithms enable augmenting, resizing, and upscaling existing materials, so they can potentially improve the effectiveness of marketing campaigns.
FAQ
Summing up
Diffusion models have transformed generative AI by enabling stable, high-quality image and video generation through a more efficient approach than earlier techniques. Stable Diffusion takes image processing into a reduced latent space, allowing organizations to create detailed visuals while using fewer computational resources. Meanwhile, newer text-to-video models continue to expand what diffusion-based systems can achieve.
The real challenge for businesses is no longer whether generative AI can create impressive results, but how to turn these capabilities into meaningful outcomes. Finding the right use cases, integrating AI into existing processes, and building solutions that align with business goals require a thoughtful approach.
Contact our AI experts to explore how diffusion models can support your business goals, validate promising use cases, and turn generative AI ideas into practical solutions.



Your business results matter
Achieve them with minimized risk through our bespoke innovation capabilities. Fill in the form below.