






Machine learning vs traditional programming: key differences explained


July 20, 2026 9 min read 204 views
Machine learning has become one of the driving forces behind modern AI, powering everything from fraud detection and recommendation engines to predictive analytics and computer vision. But despite its rapid adoption, traditional programming remains the foundation of most software systems.
In this article, we’ll explain how these two approaches differ, how machine learning models learn from data, and where each method delivers the best results.
What is the traditional programming paradigm vs machine learning (ML)?
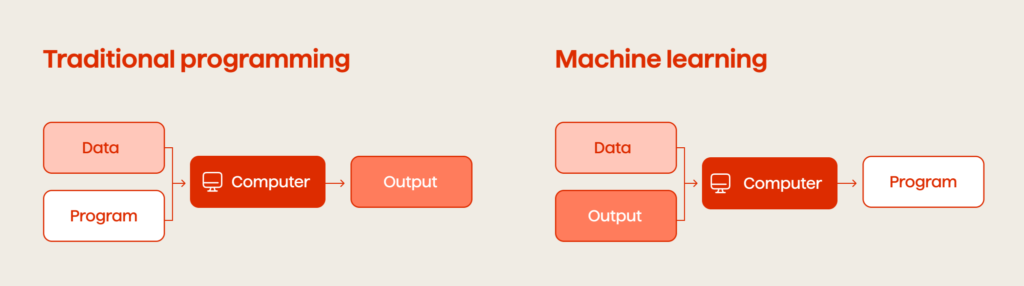
The main difference between traditional programming and machine learning is how software solves a problem. Traditional programming follows rules explicitly written by developers, while machine learning learns patterns from data to make predictions or decisions.
| Traditional programming | Machine learning |
|---|---|
| Developers define rules manually | Models learn patterns from data |
| Uses explicit programming for every scenario | Makes predictions without explicit programming for every scenario |
| Best for predictable, rule-based tasks | Best for complex problems involving patterns and large datasets |
| Output depends on predefined instructions | Output improves through training and continuous learning |
| Requires less data to function | Requires high-quality training data |
Traditional programming involves writing down the exact steps required to solve a problem. By contrast, machine learning (ML), a subset of artificial intelligence (AI), is inspired by the way humans learn. Instead of defining every rule, we provide examples and let the model determine how to solve the problem on its own.
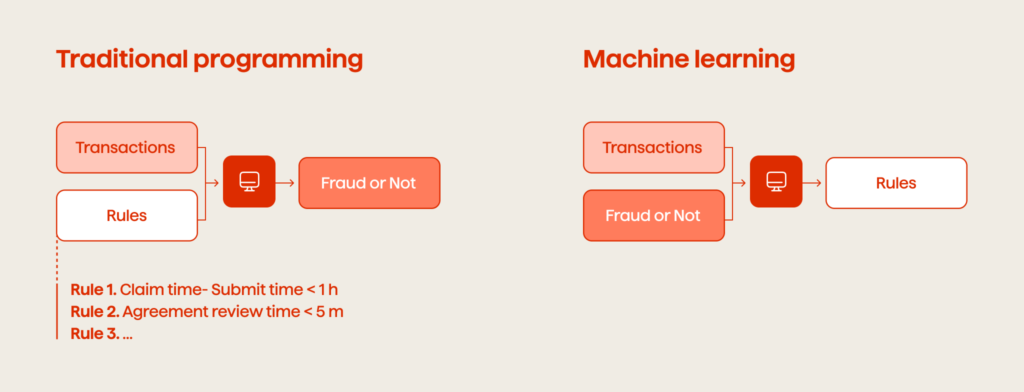
The following is a real-life example of how traditional programming and Machine Learning differ. Imagine a hypothetical insurance company that is striving for the best customer experience in the 21st digital environment, as well as preserving assets and their ROI. So, the automatic detection of fraudulent claims is a part of their business processes.
Consequently, there are 2 possible scenarios of technology stepping in:
Traditional programming (rule-based approach). In this case, we define the set of rules that will determine whether the claim is fraudulent or genuine, and then a developer translates them into code. This works great when such rules exist, and we know about them.
Unfortunately, this is not always the case in real life. We do not always know exactly what rules a program should follow. The insurance agent’s rule which reads: ‘this case looks suspicious: deny the claim’ is difficult to translate into code, isn’t it? Let alone the image classification problem, where it’s almost impossible to come up with the rules that will allow us to differentiate between cats and dogs. And that’s exactly where Machine Learning comes into play. The main property of Machine Learning algorithms is the ability to find rules using existing examples.
Now you may wonder what the actual algorithm behind training the model or ‘learning’ from examples is.
Why are neural networks key to machine learning?
Artificial neural networks (ANNs) are one of the core technologies behind modern machine learning. They enable models to learn complex patterns from data, making it possible to solve tasks such as fraud detection, image classification, and speech recognition.
We’ll explain how this works using an artificial neural network (ANN) as an example. ANNs are machine learning models inspired by the networks of biological neurons found in the human brain.
ANNs are powerful scalable tools that tackle complex Machine Learning tasks, such as powering up speech recognition services, classifying billions of images, and automating fraud detection, to name just a few.
→A real case of AI-powered fraud detection
ANNs are heavily used today, although they were first introduced back in 1943. Since then, they have witnessed several rises and winter periods. But now, due to the huge quantity of data available, tremendous increase in computing power, and improved architectures, it looks like ANN is likely to have a solid impact on our lives.
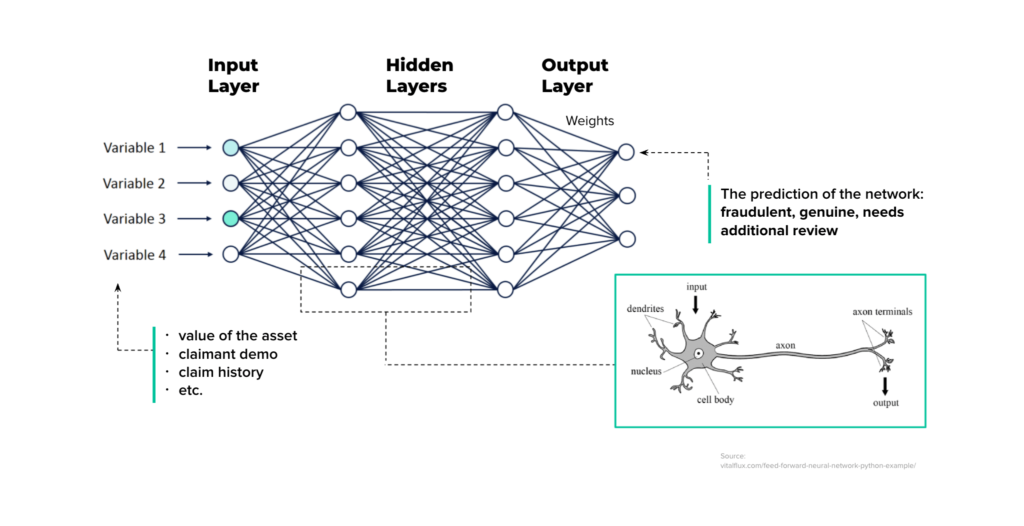
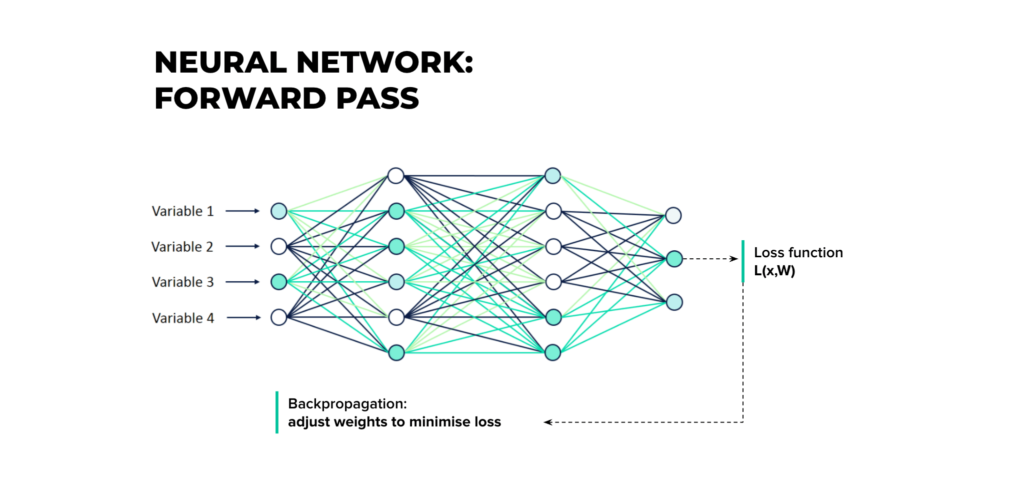
Neural networks consist of layers with each layer consisting of “neurons“. The most interesting thing is that the neurons are just decimal numbers.
The first layer of the neural network is called the input. In fact, this is your data. In the case of fraud detection, these are the features of an insurance claim (value of the asset claimed, the demo characteristics of the claimant, and so on). So, in the case of a face recognition problem, the input is the raw pixels in an image.
The last layer of the neural network is the output layer. This is actually a network prediction based on the data you entered. In our example with fraud detection, it’s a verdict: fraudulent or genuine.
All the layers are interconnected, and each connection is associated with a weight. These are also just decimal numbers. Knowing the values of the neurons of the input layer and the weights, we can calculate the values of all the other neurons in the network.
That is, the values of the neurons of the first hidden layer are calculated based on the values of the neurons of the input layer, and the connection weights between the input and the first hidden layers.
This process is called forward propagation.
But how do we know the value of the weights? Basically, we don’t. We need to learn them. And that’s actually when learning takes place. We can utilize the backpropagation training algorithm for this, which was invented back in 1986, but is still used today.
For each training instance, the backpropagation algorithm first makes a prediction (forward pass) and measures the error.
- The algorithm handles one mini-batch at a time (for example, 32 instances each) and it goes through the full training set multiple times. Each pass is called an epoch.
- The algorithm uses a loss function that compares the desired output and the output of the network and returns some measure of the error.
Then it goes through each layer in reverse order and computes the gradient of loss function with respect to every single model parameter. In other words, it measures the error contribution from each connection (reverse pass). Once we have these gradients, we know how to tweak the parameters in order to reduce the error (this is called the Gradient Descent step).
Key takeaways
Having walked through all of the above, here are some conclusions:
- We need data to train the Machine Learning algorithm. The more data, the better. According to Peter Norvig’s famous work ‘The Unreasonable Effectiveness of Data’: for complex problems the data matters more than the algorithm itself.
- Data is everywhere and it’s constantly being born on people’s edge devices like mobile phones, cameras and microphones as well as social media and transaction histories.
- Training an ML model is computationally expensive.
In a standard ML setup, data is usually collected from one or multiple clients and stored in a central storage. A Data Scientist has access to the data in the storage for doing ML.
A data scientist wants to train an AI model on the data using a predefined ML algorithm. Once the model is trained, they evaluate it on new or unseen data. If the model’s performance is not satisfactory, a data scientist makes some changes to the algorithm, does hyper-parameter tuning, or adds more data. Then they retrain and re-evaluate the model. The Data Scientist keeps doing these steps until the model reaches an accepted level of efficiency.
Once the Data Scientist is happy with the model, they deploy it to the devices where the model will be used to make inference on the device data.
What are the limitations of machine learning?
Traditional machine learning approaches often require large amounts of centralized data and significant computing resources. This can create challenges related to privacy, data availability, and the cost of training models at scale.
Some limitations of standard machine learning include:
- It requires data to be centralized on a single machine or server, or in a data center.
- As a result, it compromises the privacy of the data owners by exposing the sensitive information, at least to the developer and the centralized machine owner.
- Due to privacy concerns, the owners are not always willing to share their sensitive but useful data, which creates data scarcity.
- On top of that, training large Machine Learning algorithms on billions of data in a centralized machine or a cluster of machines is computationally very expensive.
FAQ
Machine learning vs traditional programming: choosing the right approach
Traditional programming and machine learning solve different types of problems. Traditional programming remains the right choice for predictable processes where developers can define clear rules and expected outcomes. Machine learning, on the other hand, enables systems to identify patterns, learn from data, and make predictions when explicit programming for every scenario is not practical.
In many modern applications, the most effective solutions combine traditional programming with machine learning. By understanding the strengths and limitations of each approach, businesses can choose the right technology for their specific goals.
Looking to build an AI-powered solution or explore how machine learning can support your business? Our experts can help you design and implement a strategy tailored to your needs.



Your business results matter
Achieve them with minimized risk through our bespoke innovation capabilities. Fill in the form below.