






Stereo cameras in obstacle detection: Avenga’s research


May 8, 2025 10 min read 132 views
Stereo cameras have distinct advantages over RADARs and LiDARs in certain situations.
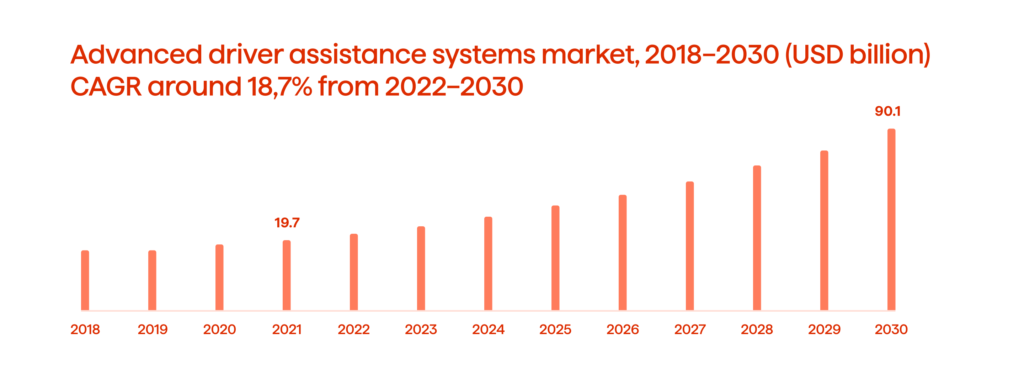
According to the World Health Organization (WHO), car crashes claim the lives of approximately 1.3 million people every year. With such alarming statistics, advanced driver assistance systems (ADAS) have become critical in the quest for safer roads. The ADAS market is expected to reach $91 billion by 2030 as depicted in Figure 1.
An ADAS consists of sensors, chips, an interface, a powerful processor, and software algorithms that are all aimed at enhancing driver performance, increasing safety, and improving the in-vehicle experience. Additionally, ADAS is a steppingstone toward achieving fully autonomous driving.
ADAS incorporates various features such as adaptive cruise control, departure warning, blind spot detection, and collision avoidance. They assist drivers by providing timely alerts or taking preemptive measures in emergency situations.
At the heart of these systems are sensors that collect environmental data. Whether RADARs, LIDARs, or cameras, these sensors are undoubtedly the most crucial element of ADAS as they help address the main challenges, such as obstacle detection, and serve as the foundation for all the sophisticated ADAS features.
Understandably, if the processing technology is too advanced, faulty, inconsistent, or has incomplete data from the sensors, they can render the entire ADAS ineffective.
As a long-term technology partner to many prominent auto manufacturers and automotive startups, Avenga recognizes the importance of constantly expanding our expertise in the field. Through the testing and examination of the newest ADAS trends, we are able to gain valuable insights into the capabilities of emerging technologies and explore optimization and growth opportunities for our clients.
To this end, we continuously invest in and carry out various R&D initiatives in ADAS. Our recent experimentation with stereo cameras and advanced neural network architectures for obstacle detection has yielded promising results. In this article, we will delve into the different types of sensors utilized in ADAS for obstacle detection and provide details of our ongoing lab project.
Monocular Cameras
Cameras are one of the oldest and most established types of sensors. They provide high-resolution images and a wide range of information about the scene, including colors, shapes, and textures. With their excellent semantic capabilities, they can interpret visual data in a way that approximates human understanding and are adept at detecting lateral motion and movement. However, cameras also have limitations in obstacle detection, such as difficulty with accurate depth perception and low-light conditions, or obstructions that can impede their view.
Despite being recognized for their potential for ADAS, manufacturers were unable to fully utilize them in the past, mainly due to their limited computational capabilities and a lack of deep learning systems that could deliver the needed levels of required accuracy.
LiDAR
LiDAR is a powerful sensor providing a range accuracy of +/- 5 cm to +/- 10 cm and a range resolution of around 2 cm to 10 cm. It consistently performs better in distances up to 50 meters or less (the typical range for many ADAS applications) than conventional cameras and RADARs. This makes LiDARs a great choice for 3D mapping and modeling applications. Their ability to discern objects based on their unique 3D shape and location not only enables simultaneous tracking of multiple items but also serves as a vital feature for achieving precise awareness of the environment.
Despite these benefits, LiDARs do have some drawbacks too. They operate by producing point clouds with lower spatial resolution than camera images, and the density of those points can only be increased with repeated scanning or the utilization of multiple sensors. In other words, LiDARs are inherently lower resolution than cameras, and to capture a complete picture of the environment they need to scan their surroundings multiple times, which takes time. Additionally, it’s been shown that LiDARs tend to be ineffective at predicting the road’s location, which is crucial for identifying if there is an obstacle in the road.
The LiDARs’ price is its most significant drawback though. Calculating the photon’s speed requires gigahertz of computing power, which makes LiDAR-based ADAS systems expensive to develop and use. Moreover, they typically have many moving parts (which increases damage vulnerability) and their reliance on lasers, known to have a short lifespan, further compounds the issue.
It should be mentioned that there also exist Solid State LiDARs that utilize a solitary laser for scanning the environment and feature minimal or no moving components. They seem to hold some potential, but they also have major limitations, such as increased bulkiness, reduced field of vision, and higher costs.
RADARs
RADAR sensors are widely used in ADAS too, but for different reasons. Unlike LiDARs and cameras, they are relatively inexpensive and can withstand harsh weather conditions, such as fog, rain, and snow. The radio waves that RADARs emit can travel well under all weather conditions, ensuring their accuracy remains unaffected when visibility is low. They are excellent at measuring the distance to objects, particularly metal ones, and can estimate velocity fairly easily, as opposed to cameras.
That being said, RADARs have significantly lower resolution than cameras and LiDARs. For vertical resolution, multiple antennas are typically required. This is a major limitation in the context of object detection. RADARs are often unable to distinguish between objects above or at car level as well as provide the detailed information needed for object categorization. It is also worth noting that their signal can be interfered with by other signals, such as radio waves from other radar units or sources in the environment, which may lead to false detections and inaccurate measurements.
Stereo Cameras
Now, we come to the technology that Avenga has spent significant time experimenting with – stereo cameras. While we were assessing and testing various technological approaches to real-time obstacle detection, the research clearly showed that stereo cameras have plenty of untapped potential. We identified their incorporation into the ADAS systems as a promising means of providing profound benefits to our clients.
What Are Stereo Cameras?
As humans, we have points in our left and right eyes that correspond to one another, and we can use those to determine how close or far an object is. One eye, individually, can also provide various cues for our brain to estimate depth, but true 3D depth perception is only possible with both eyes. A similar principle is applied in the stereo vision systems in ADAS.
The basic idea is to put two cameras at a fixed distance horizontally so that they simultaneously capture scenes from right and left angles. Then, the images are run through a processor to find the pixels representing the same object in the scene and extract depth information using stereo triangulation.

The triangulation principle uses the relationship between the distance to the object, the baseline (distance between the cameras), the disparity (the difference in the horizontal position of the object in the left and right images), and the focal length (the distance between the camera length and the image sensor).
The disparity is calculated after an algorithm finds the features (edges, corners, etc.) that can be matched between the two images so as to determine corresponding points, and then the horizontal distance between them is measured. Finally, the depth is computed with a formula:
depth = (baseline * focal length) / disparity
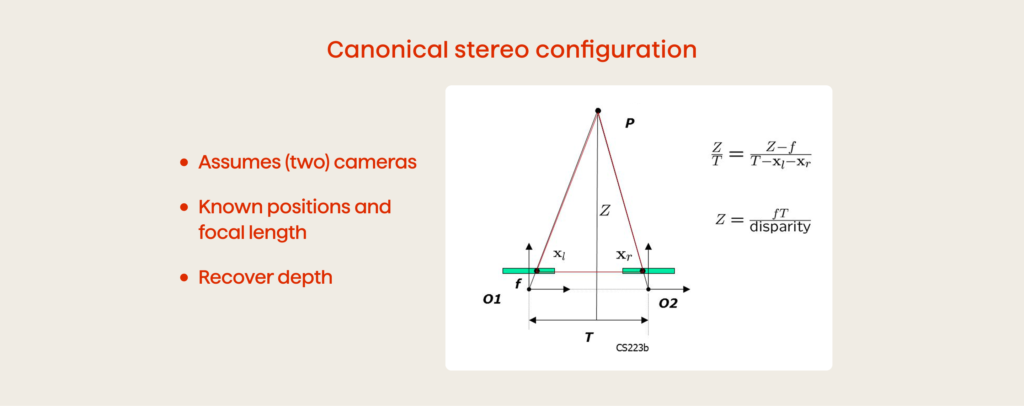
As shown in Figure 3, the larger the disparity, the smaller the depth, and vice versa. In other words, the larger the disparity, the closer the object is to the cameras.
Modern stereo vision systems, which are essentially implementations of the triangulation principle, calculate depth information in a nuanced way using sophisticated computer vision methods. These algorithms typically have four stages: matching cost computation, cost aggregation, disparity optimization and selection, and disparity refinement. All of these phases are aimed at creating and tuning disparity maps that show the differences between corresponding pixels in images which ultimately enable the recovery of the 3D structure within the scene.
Matching cost computation: The similarity between corresponding pixels in the left and right images (called matching costs) is computed. This is usually done by comparing gradients, intensity or color values, and other image features.
Cost aggregation: The matching costs for each pixel are combined with the costs of neighboring pixels. The noise and inconsistencies are then reduced, enabling the creation of accurate disparity maps.
Disparity optimization and selection: This is the search for the best matching disparity value for each pixel, given the aggregated matching costs. Various optimization techniques can be used here. This step results in the algorithm selecting the optimal disparity value for each pixel based on certain criteria, such as the smoothness of the disparity map.
Disparity refinement: The refinement of the disparity map involves post-processing techniques such as sub-pixel interpolation, edge-preserving filtering, or occlusion handling. This further removes uncertainty and noise in the disparity map and helps elevate the accuracy and robustness of the stereo vision system, especially in challenging environments or with complex scenes.
Another important thing we must mention here is the cost volume, a data structure that facilitates the computation of matching costs between the pixels in different images. Basically, it is a grid or a tensor that stores the matching cost values of pixels in two images. It can also be thought of as a 3D matrix, where the dimensions correspond to coordinates (height and width) and the disparity range. Each element represents the matching cost between a pixel in one image and a candidate pixel in the other image at a specific disparity level.
Concise and informative representation is crucial in stereo matching. At Avenga, we have been successfully using the Attention Concatenation Volume (ACV) method to achieve elevated stereo vision accuracy. This method relies on attention mechanisms to enhance information aggregation across multiple image scales. It suppresses redundant information while highlighting the matching-related data. Incorporating ACV into a stereo-matching network has allowed us to achieve better performance while utilizing a far more lightweight aggregation network. Moreover, by slightly tweaking the ACV to produce disparity hypotheses and attention weights from low-resolution correlation clues, we can achieve real-time performance in obstacle detection. This way, the network can attain similar levels of accuracy at a significantly reduced memory and computational cost.
Final Words
As our indoor experiments have proved, stereo cameras do have distinct advantages over LiDARs, which still are powerful sensors with their own strengths. This includes their ability to capture rich visual information such as color, texture, and object shape, which can provide important cues for object detection, segmentation, and recognition.
Additionally, stereo cameras also offer a higher spatial resolution and a wider field of view than LiDARs, which can contribute to the generation of more detailed and comprehensive scene information. Stereo cameras can capture high-resolution images with pixel-level accuracy, making them especially useful for detecting small or thin objects such as wires, poles, or signs.
Unlike LiDARs, stereo cameras are robust to occlusions and other obstacles such as rain, fog, or dust. LiDARs lasers can be blocked or scattered by objects in the environment, and this might result in incomplete or noisy depth maps. In contrast, stereo cameras can use texture or color information to infer the depth of occluded or partially visible objects. They can compensate for visual artifacts using advanced algorithms such as multi-view stereo.
Finally, stereo cameras are generally less expensive and consume less power than LiDARs, making them a more cost-effective option for cost-sensitive or resource-constrained applications.
If you’d like to get more in-depth insights into the utilization of stereo cameras and other innovative technological approaches for precise obstacle detection, contact us right now and promptly get in touch with one of our esteemed experts. They are well-equipped to provide you with comprehensive information and assistance.



Your business results matter
Achieve them with minimized risk through our bespoke innovation capabilities. Fill in the form below.