





How To Prepare Your Pharma Data For AI Consumption


May 6, 2025 18 min read 51 views
Amazon launched a purpose-built service for bioinformaticians, scientists, and researchers that reinvents the handling of genomic, transcriptomic, and other omics data.
The res Explore the stages of making pharmaceutical data ready for AI models.
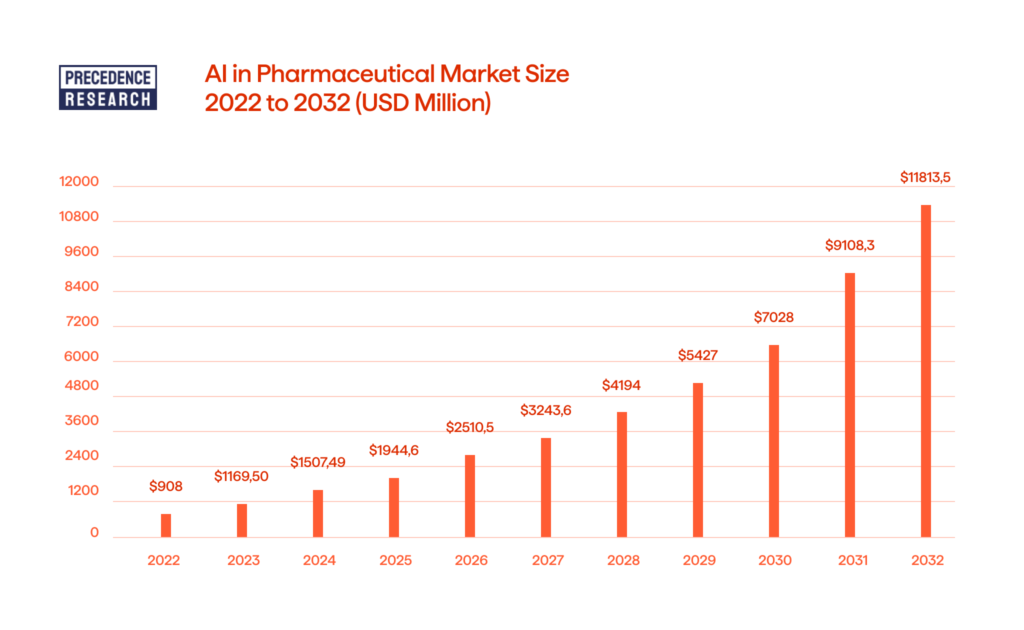
The global market for AI in pharmaceuticals is projected to reach over USD 11,813.56 million by 2032, as per Precedence Research. When implemented effectively, AI models can empower organizations to reshape business models, streamline processes, and enhance everything from drug research to clinical trial data flow. However, to ensure they become valuable assets, rather than just experimental trendy tools with little tangible benefit, one crucial foundation is necessary: proper data preparation.
This article will guide you through the stages of preparing pharmaceutical datasets for AI consumption to ensure reliable results.
Data Structure Analysis
The first step in preparing data for AI is structure analysis. It ensures the data is consistent, well-organized, and ready for AI algorithms to interpret effectively.
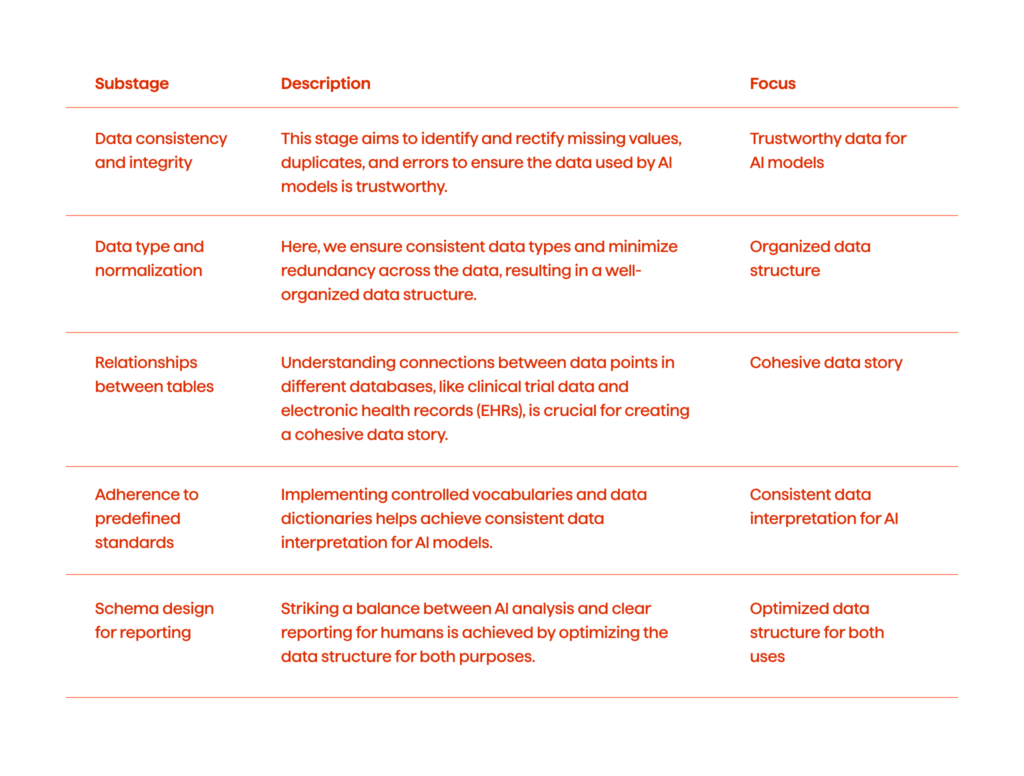
Data Consistency And Integrity
Here, we aim to establish trust in the data by identifying and rectifying issues that can mislead the models.
- Missing values. Missing data points on clinical trial participants, drug properties, or adverse event reports can skew models’ outputs. To address this, we can implement imputation techniques that fit pharmaceutical data like using the mean for continuous variables or the last observation carried forward (LOCF) for longitudinal studies.
- Duplicates. Duplicate patient records or compound entries can lead to inflated results. We can apply cleansing routines to identify and merge duplicates based on unique identifiers like patient IDs or compound structure fingerprints.
- Errors. Transcription errors in dosage amounts or inconsistencies in units (mg vs. g) can be disastrous for models’ data understanding. Data validation rules are needed to enforce data type restrictions, including expected value ranges specific to pharmaceutical data (e.g., ensuring valid dosage ranges for specific medications).
Analyzing Data Structure And Normalization
This stage involves assessing the organization of data, including data types, formats, and redundancies. Here’s exactly what we can do:
- Data types. Ensuring data types are aligned with typical pharmaceutical datasets. For example, this could mean enforcing consistent date formats for clinical trial entries and standardizing units for measurements like concentration or volume.
- Redundancy. Repetitive information across tables can bloat data size and lead to inconsistencies. Data normalization techniques can help create a streamlined structure, minimizing redundancy while preserving data integrity.
Analyzing Data Relationships Between Tables
It’s extremely important to us to understand how data points in different databases, like clinical trial data and electronic health records (EHRs), connect and tell a cohesive story. These are some of the steps we could implement here:
- Relationships. Identifying primary and foreign keys that link data points across tables. For instance, a patient ID in a clinical trial database might link to a diagnosis table in the EHR system.
- Entity-relationship diagrams (ERDs). These connections can be visualized using ERDs tailored to the pharmaceutical domain, which can depict relationships between patients, drugs, diagnoses, and treatment outcomes.
Adherence To Predefined Standards
In this stage, we create unified naming conventions and schema designs. Here’s how:
- Standardized naming. Implementing controlled vocabularies for drug names, diagnoses, and medical procedures. This consistency allows AI models to recognize and interpret entities accurately.
- Data dictionaries. Data dictionaries are also very useful for defining data elements. They can include details like data type, allowed values, and units specific to pharmaceutical research.
Defining The Approach To Build Schema For Reports Usage
When working on data, we should always strive to design a data structure that facilitates not only AI analysis but also the generation of clear reports for human consumption. Here are some key measures to achieve this:
- Descriptive naming. Using clear and descriptive column names that reflect the meaning of the data (e.g., “Dosage_mg” instead of just “Dosage”).
- Schema comments. Including comments within the schema to explain the purpose of specific tables and columns.
- Data lineage. Tracking the origin and transformations applied to the data.
- Schema design for reporting. Applying schema designs, like star schema or snowflake schema, that are optimized for efficient aggregation and reporting alongside AI workflows. These structures allow for easy data extraction and enable us to generate informative reports on clinical trials, drug safety, and treatment outcomes.
By meticulously addressing these substages, we ensure the data structure is optimized to the point where we can feed it to AI. The focus here is on getting clean, consistent, and well-organized data that will empower AI models to deliver insights that can truly enhance various drug discovery processes, improve clinical trial design, and ultimately, benefit patient care.
Data Accuracy Analysis
Next, we tackle data accuracy. AI algorithms are only as good as the data they’re fed, so ensuring that all the training information is accurate is paramount for generating reliable insights later on.
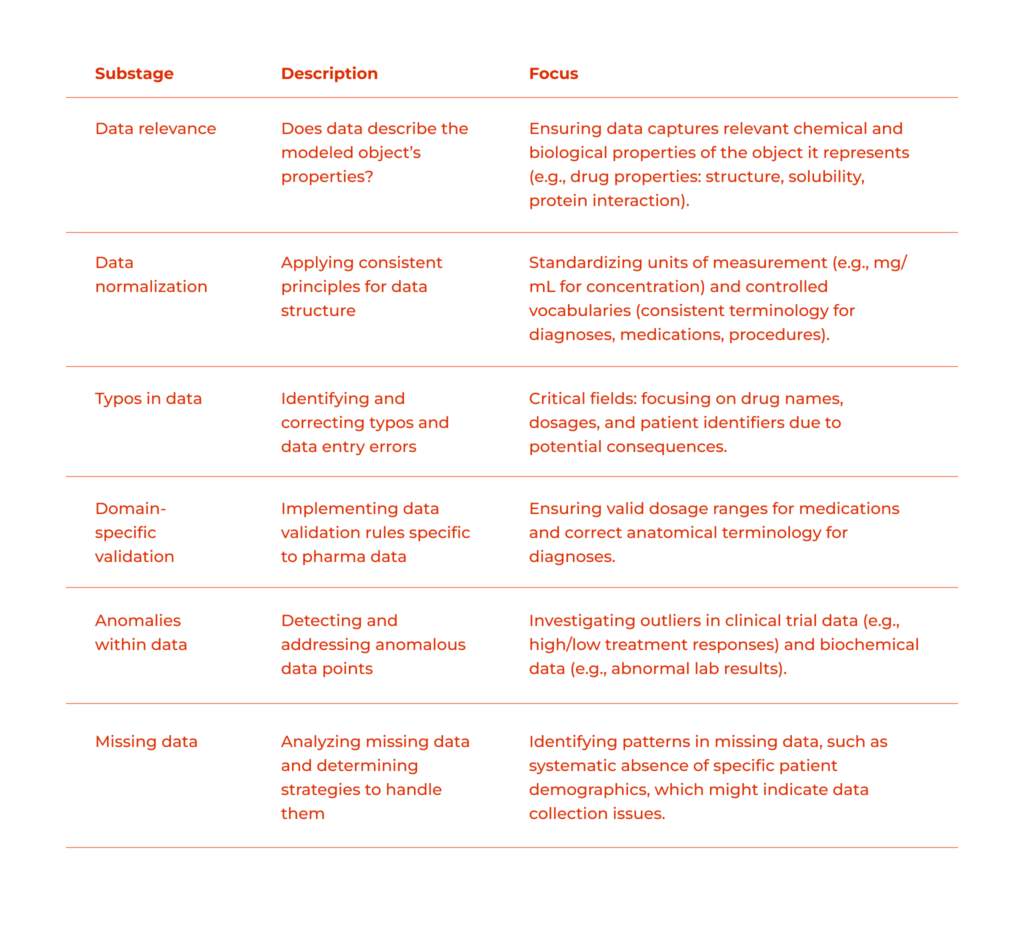
Does The Data Describe The Properties Of The Object It Models?
We should assess if the data accurately reflects the characteristics of the real-world objects it represents, and if the model, trained on this particular dataset, will be able to make correct predictions within the task it is meant to. Here are some examples:
- Drug properties. Ensuring that data wholistically captures relevant chemical and biological properties of compounds. This might include data on molecular structure, solubility, and potential interactions with target proteins.
- Clinical trial data. Verifying that clinical trial data accurately reflect patient demographics, treatment regimens, and observed outcomes.
- EHR data. Evaluating whether the EHR info accurately captures diagnoses, medications used, and patient responses to treatments.
Data Normalization
In data normalization, we apply the same principles and conventions established during data structure analysis.
- Standardized units. Ensuring consistent units of measurement across the data. This is crucial for pharmacokinetic and pharmacodynamic modeling, where units like concentration, volume, and dosage need to be standardized (e.g., mg/mL for drug concentration).
- Controlled vocabularies. Maintaining consistent terminology for diagnoses, medications, and medical procedures. This avoids misinterpretations by AI models and ensures accurate analysis.
Typos In Data
We identify and rectify typos and data entry errors that can mislead AI models. This is how we go about it:
- Critical fields. Identifying typos in critical fields like drug names, dosages, and patient identifiers. Even minor errors in these areas can have significant and dire consequences as far as model usefulness goes.
- Domain-specific validation. Implementing data validation rules specific to pharmaceutical data. This can involve checking for valid dosage ranges for specific medications or ensuring correct anatomical terminology for diagnoses.
Anomalies Within Data
Here, we detect and address anomalous data points that deviate significantly from the expected range. This is how:
- Clinical trial outliers. Investigating outliers in clinical trial data, such as unexpectedly high or low treatment responses. These could indicate genuine biological effects or data collection errors.
- Biochemical outliers. Identifying outliers in biochemical data, like abnormal lab results. These might point to errors or rare medical conditions that need further investigation.
Missing Data
Finally, we analyze the distribution of missing values across different data points and determine appropriate strategies to handle them. We Identify patterns in missing data and analyze them – the systematic absence of specific patient demographics, for example, might indicate data collection issues.
Building reliable models in pharma research demands meticulous data verification. This includes ensuring data captures relevant chemical and biological properties, reflecting real-world experiences. Standardized units, controlled vocabularies, and error correction are crucial for consistency and data integrity. Identifying anomalies and missing data management further guarantees robust and reliable models.
Data Uniqueness Check
Duplicate data points can inflate sample sizes and ultimately lead to misleading AI-driven insights. This is why we need a comprehensive data uniqueness check involving several phases.
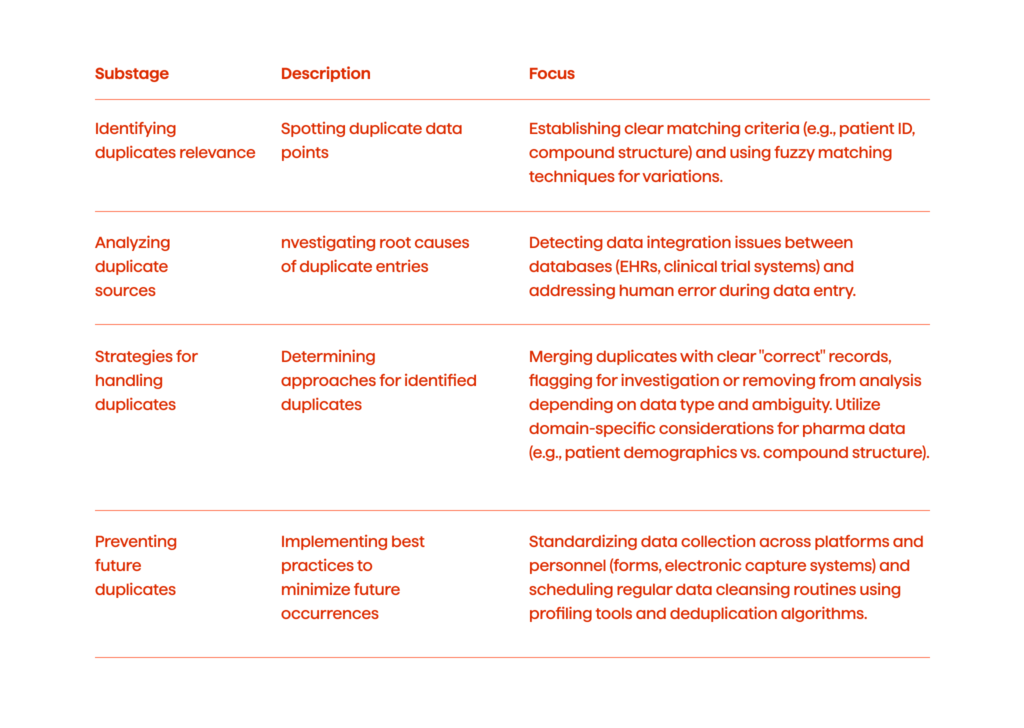
Identifying Duplicates
We spot duplicates by doing the following:
- Matching criteria. First, we establish clear matching criteria for identifying duplicates. This might involve factors like patient ID, compound structure, demographic details, and clinical trial identifiers.
- Fuzzy matching. Then, we implement fuzzy matching techniques to account for potential variations in data entry. For instance, we can consider slight variations in the spelling of patient names or inconsistencies in date formats.
Analyzing Duplicate Sources
Then, we investigate the root causes of duplicate entries to prevent future occurrences. These are the issues we should pay special attention to:
- Data integration issues. Detecting issues arising from data integration between different databases, such as EHRs and clinical trial management systems. Standardize data collection processes across platforms to minimize duplicate entries.
- Human error. Addressing potential human errors during data entry. Implementing data validation rules and enforcing controlled vocabularies to minimize typos and inconsistencies.
Strategies For Handling Duplicates
We must determine the most appropriate approach to handle identified duplicates based on the particular goals of our future analysis.
- Merging duplicates. We can merge while retaining relevant data points from each instance (for cases with clear identification of the “correct” record).
- Flagging and removal. Depending on the nature of the data, we can flag duplicates for further investigation or remove them from the analysis dataset (if the “correct” record is ambiguous).
- Domain-specific considerations. When it comes to pharmaceutical data, we must always tailor our strategy to the specific data type. For instance, duplicates in patient demographics might require a different approach compared to duplicates in compound structure data.
Some of the best practices for preventing the occurrence of duplicates in the future:
- Standardized data collection. Ensuring consistent data collection practices across all platforms and personnel involved. Utilizing standardized forms and electronic data capture systems to minimize human error.
- Data cleansing routines. Scheduling regular data cleansing routines to identify and address duplicates before they impact analysis. This can involve applying data profiling tools and deduplication algorithms.
In pharma research, trustworthy AI hinges on unique data. We achieve this by identifying duplicates, investigating their root cause, and implementing standardized collection practices. Finally, clear duplicates are merged, while others are flagged. This multi-phased approach, coupled with data cleansing routines, ensures clean data for robust AI analysis.
Learn about how we built an innovative drug ordering system for QPharma. Success story
Data Existence Check
Missing data points, particularly in time-based, location-based, or user-based contexts, can lead to biased models and incomplete insights. So, here’s what we can do to address the issue:
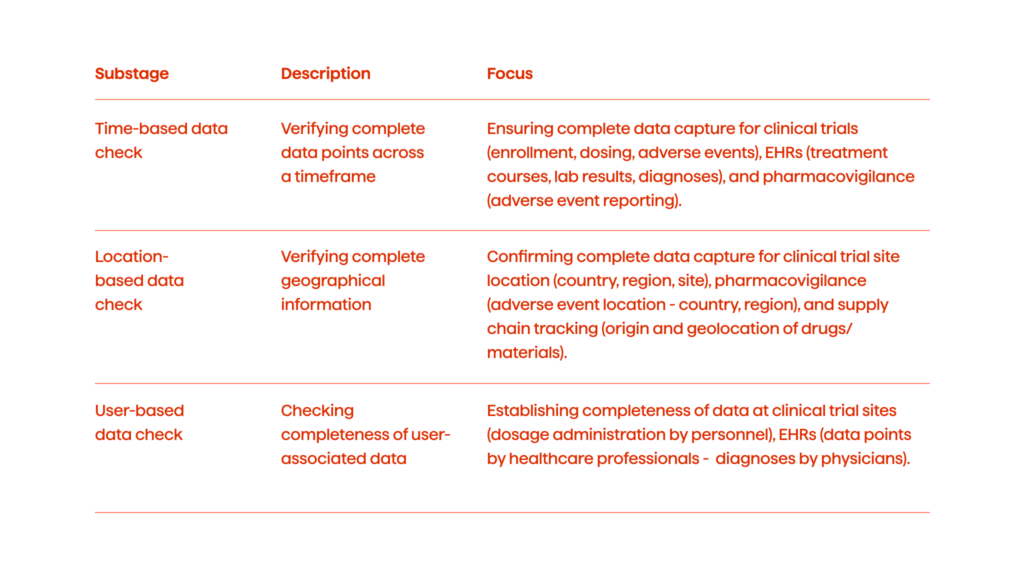
Time-Based Data Check
This step is about verifying the presence of complete data points across the relevant timeframe for analysis.
- Clinical trials. Ensuring complete data capture for all clinical trial phases, including patient enrollment, dosing schedules, and adverse event reporting throughout the study duration.
- EHR data. Verifying the existence of relevant clinical data points across a patient’s medical history, checking if all the treatment courses, lab results, and diagnoses have complete records.
- Pharmacovigilance. For pharmacovigilance (drug safety monitoring), we need exhaustive reporting of adverse events throughout the post-marketing surveillance period.
Location-Based Data Check
This step is basically the same as the previous one, but in regards to geographical information.
- Clinical trial sites. Confirming complete data capture of patient enrollment location, potentially including country, region, and specific clinical trial site information.
- Pharmacovigilance. Verifying the location (country and potentially region) where the adverse event occurred to identify potential geographic trends.
- Supply chain tracking. Assessing if the data is complete on the origin and geolocation of manufactured drugs and raw materials.
User-Based Data Check
This is about checking whether the information we have associated with specific data collectors or users is comprehensive enough.
- Clinical trial data. Establishing the completeness of data at each clinical trial site, including information like dosage administration recorded by specific research personnel.
- EHR data. Checking the presence of data points entered by specific healthcare professionals involved in a patient’s care, like diagnoses recorded by physicians.
Ensuring data existence involves verifying the presence of comprehensive data across time-based, location-based, and user-based contexts. For time-based data, it’s crucial to verify all clinical trial phases, patient medical histories, and pharmacovigilance reports are thoroughly captured. Location-based checks confirm the comprehensiveness of geographical information for clinical trial sites, adverse event locations, and supply chain origins. User-based checks focus on the data associated with specific data collectors, healthcare professionals, and data provenance tracking.
Data Augmentation And Synthetic Data Generation
Data scarcity is a significant hurdle in pharmaceutical research, particularly in areas like rare disease research and clinical trials with limited patient populations. Traditional approaches might be limited by the availability of real-world data. This is where data augmentation and synthetic data generation come into play.
Data Augmentation
Data augmentation involves manipulating existing data to create new, artificial data points, which helps to expand the dataset size and improve model generalizability. Here’s how this works in the pharma context:
- Image augmentation (medical imaging). Techniques like rotation, flipping, cropping, and noise injection can be used on medical images (e.g., X-rays, CT scans) to create variations that enhance the model’s ability to recognize subtle disease patterns.
- EHR data. Adding synthetic noise to anonymized patient data points (while maintaining privacy) to improve model robustness to real-world variations.
Synthetic Data Generation
Synthetic data generation involves creating entirely new, artificial data points that statistically resemble real-world data. This is where how it could be used:
- Rare disease research. Simulating patient data with specific rare disease characteristics can help develop and test machine learning models for diagnosis and treatment prediction.
- Clinical trial design. Generating synthetic patient populations with varying disease severities and responses to existing treatments can be used to optimize clinical trial design and patient selection.
- Drug discovery. Synthetic compound libraries can be created to virtually screen for potential drug candidates, accelerating the initial stages of drug discovery.
When talking about augmenting pharma datasets, we should also list some important considerations.
- Data quality. Both data augmentation and synthetic data generation rely heavily on the quality of the original data. Biases in the original dataset will most likely be amplified in the augmented or synthetic data.
- Validation. It’s crucial to validate the generated data to ensure it reflects real-world characteristics and doesn’t introduce misleading patterns.
- Regulatory compliance. Pharmaceutical research needs to adhere to strict regulatory guidelines. The use of augmented or synthetic data should be transparently documented and meet regulatory approval.
In summary, data augmentation manipulates existing data to create new variations, improving model generalizability. Synthetic data generation creates entirely new data points that mimic real-world data, aiding in rare disease research, clinical trial design, and drug discovery. Key considerations for these methods include ensuring high data quality to avoid amplifying biases, validating generated data to maintain real-world accuracy, and adhering to regulatory compliance for transparency and approval in pharmaceutical research.
Data Annotation And Labeling
Unlike the foundational stages of data preparation that ensure cleanliness and organization, data annotation injects meaning into the data.
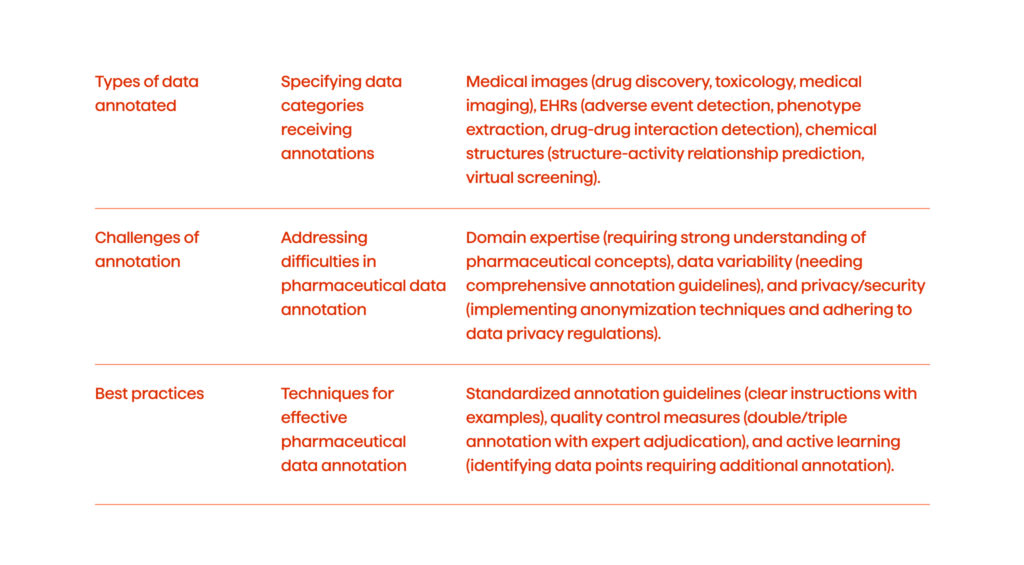
Types Of Data Annotated In Pharma
- Medical images. Annotations play a crucial role in training computer vision models used in pharmaceutical research. Here are some examples:
- Drug discovery. Annotating microscopic images of cells or protein structures to help models identify potential drug targets or predict drug interactions.
- Toxicology. Labeling images from animal studies to train models for detecting drug-induced toxicity or tissue damage.
- Medical imaging (e.g., X-rays, CT scans). Annotating these images to help models diagnose diseases, assess treatment response, or monitor disease progression relevant to clinical trials.
- EHR. NLP techniques come into play here to process and extract meaningful information from vast amounts of unstructured text data in EHR. Examples include:
- Adverse event (AE) detection. Annotating clinical text reports to train models for identifying and classifying adverse events associated with medications.
- Phenotype extraction. Labeling patient medical history data to train models for identifying specific patient populations or disease phenotypes relevant to drug development.
- Drug-drug Interaction (DDI) detection. Annotating medication lists and treatment plans to train models for flagging potential drug-drug interactions.
- Chemical structures. Chemical compound information is crucial for drug discovery. Here’s how annotation aids AI models:
- Structure-activity relationship (SAR) prediction. Labeling chemical structures alongside their biological activity allows models to predict the activity of new compounds based on their structure.
- Virtual screening. Annotating desired drug properties helps models virtually screen large libraries of compounds to identify potential drug candidates.
In this section, we must also address why pharmaceutical data annotation can be challenging.
- Domain expertise. To ensure accurate labeling, annotators need a strong understanding of pharmaceutical concepts, medical terminology, and relevant regulations.
- Data variability. Medical images, EHR text data, and chemical structures can exhibit high variability, requiring comprehensive annotation guidelines to maintain consistency.
- Privacy and security. Pharmaceutical data often contains sensitive patient information. Implementing robust anonymization techniques and adhering to data privacy regulations are essential during annotation processes.
Some of the best practices for pharmaceutical data annotation.
- Standardized annotation guidelines. Developing clear and well-defined annotation guidelines with examples helps ensure consistency and reduces ambiguity for annotators.
- Quality control measures. Implementing double or triple annotation with adjudication by experts helps identify and rectify labeling errors.
- Active learning. Incorporating active learning techniques allows models to identify data points that require additional annotation, optimizing the annotation process.
Data annotation in pharmaceutical research transforms raw data into a structured, meaningful format, enabling AI models to interpret complex datasets accurately. This process involves labeling medical images, EHRs, and chemical structures to support drug discovery, toxicology assessments, disease diagnosis, adverse event detection, phenotype extraction, and drug-drug interaction identification.
Data Anonymization
Data anonymization tackles a critical ethical and legal hurdle in pharmaceutical research: patient privacy. Pharmaceutical datasets are brimming with sensitive information, from demographics and medical history to treatment details and potentially even genetic data. Here are some of the common techniques that could be used for data protection:

- Pseudonymization. Replacing patient identifiers (names, IDs) with unique codes. While not truly anonymized, it offers a layer of protection if the key to decoding the codes is safeguarded.
- Data minimization. Limiting the collection of patient data to only what’s strictly necessary for the research reduces privacy risks.
- Generalization. Applying techniques like date rounding (e.g., year of birth instead of exact date) or using broader geographical locations can reduce the risk of re-identification.
- Data masking. Replacing sensitive data points with fictional values while preserving data utility for analysis (e.g., replacing a patient’s age range with a broader category).
- Data aggregation. Analyzing anonymized data in aggregate form (e.g., analyzing trends in disease prevalence without linking it to specific patients).
And here are some of the challenges of data anonymization.
- Data completeness. Excessive anonymization might remove crucial details, hindering the research value of the data. Finding the right balance is key.
- Data provenance. Tracking the origin and modifications made to anonymized data is essential to ensure its integrity and prevent misuse.
Best practices for data anonymization
- Risk assessment. Identifying the specific privacy risks associated with the data being collected and used.
- Multi-layered approach. Combining different anonymization techniques to create robust protection.
- Data governance framework. Establishing clear policies and procedures for handling and anonymizing patient data.
- Regular review. Periodically evaluating the effectiveness of anonymization techniques and updating them as needed.
By implementing a combination of anonymization techniques like pseudonymization, data minimization, and controlled generalization, pharmaceutical research can strike a crucial balance. This balance safeguards patient privacy while ensuring data remains valuable for scientific progress.
Summing Up
In essence, meticulous data preparation bridges the gap between raw pharmaceutical data and the transformative power of AI. This refined data empowers AI models to generate insights that can significantly enhance how pharma and life sciences companies operate. The process requires not only the robust data practices outlined here, but also a tight collaboration between data scientists and pharmaceutical experts.
Furthermore, transparent documentation and a scalable data architecture are essential for building trust and ensuring the long-term success of your AI endeavors.
Want to unlock the potential of AI in your organization? Whether you’d like to learn more about how meticulous data preparation paves the way for AI-powered breakthroughs, or want to launch an AI project that can enhance drug discovery, optimize clinical trials, or improve patient care, contact us today for a free consultation.


Closed loop marketing (CLM) in pharma

Supply chain risk management with data analytics
Your business results matter
Achieve them with minimized risk through our bespoke innovation capabilities. Fill in the form below.